
深層学習(ディープラーニング)は、近年急速に発展してきた技術の一つです。
Chainer、PyTorch、TensorFlowは、これらの深層学習モデルを実装し、効率的に学習するための主要なフレームワークです。
この記事では、Chainer、PyTorch、TensorFlowを使用した簡単なCNNの実装について紹介します。
簡単な場合ということで、今回はMNISTの分類モデルを各フレームワークを使って作ってみます。
いずれも簡単な例から試しながらコードでやっていることを理解すると、実務など別の問題も書きやすくなりますし、他の種類の深層学習への参入もグッと楽になります。
各フレームワークの実装コードを例示しますので、皆さんの学習の参考になれば幸いです。
データの準備
前述の通り、今回の記事で使うMNISTデータセットをダウンロードしておきます。
import urllib
from sklearn.datasets import fetch_mldata
try:
mnist = fetch_mldata('MNIST original')
except urllib.error.HTTPError as ex:
from six.moves import urllib
from scipy.io import loadmat
import os
print('Could not download MNIST data from mldata.org, trying alternative...')
mnist_alternative_url = 'https://github.com/amplab/datascience-sp14/raw/master/lab7/mldata/mnist-original.mat'
mnist_path = './mnist-original.mat'
response = urllib.request.urlopen(mnist_alternative_url)
with open(mnist_path, 'wb') as f:
content = response.read()
f.write(content)
mnist_raw = loadmat(mnist_path)
mnist = {
"data": mnist_raw['data'].T,
"target": mnist_raw['label'][0],
"COL_NAMES": ['label', 'data'],
"DESCR": 'mldata.org dataset: mnist-original',
}
print('Success!')
mnist['data'] = mnist['data'].astype(np.float32).reshape(len(mnist['data']), 28, 28, 1) # image data
mnist['data'] /= 255
mnist['target'] = mnist['target'].astype(np.int32) # label data
mnist['data'].shape, mnist['target'].shape # ((70000, 28, 28, 1), (70000,))
ChainerによるCNNの実装
Chainerの場合は、Classifierクラス・Trainerクラスを使った書き方もでき、とても便利です。
本記事では、これらのクラスを使わない、生の書き方とクラスを使った書き方の両方を記そうと思います。
まずはClassifierクラス・Trainerクラスを使わない場合の書き方が以下の通りです。
import datetime
import numpy as np
import matplotlib
import matplotlib.pylab as plt
import seaborn as sns
from sklearn import model_selection, metrics
import chainer
import chainer.functions as F
import chainer.links as L
from chainer.training import extensions
# train data size : validation data size= 8 : 2
train_x, valid_x, train_y, valid_y = model_selection.train_test_split(mnist['data'], mnist['target'], test_size=0.2)
# モデルクラス定義
class CNN(chainer.Chain):
def __init__(self):
super(CNN, self).__init__(
conv1 = L.Convolution2D(None, 20, 5),
conv2 = L.Convolution2D(20, 50, 5),
l1 = L.Linear(800, 500),
l2 = L.Linear(500, 500),
l3 = L.Linear(500, 10, initialW=np.zeros((10, 500), dtype=np.float32))
)
def __call__(self, x, t=None, train=False):
x = chainer.Variable(x)
if train:
t = chainer.Variable(t)
h = F.max_pooling_2d(F.relu(self.conv1(x)), 2)
h = F.max_pooling_2d(F.relu(self.conv2(h)), 2)
h = F.relu(self.l1(h))
h = F.relu(self.l2(h))
y = F.softmax(self.l3(h), axis=1)
if train:
loss, accuracy = F.softmax_cross_entropy(y, t), F.accuracy(y, t)
return loss, accuracy
else:
return np.argmax(y.data, axis=1)
def reset(self):
self.zerograds() # 勾配の初期化
# モデルとオプティマイザの準備
gpu = 0
model = CNN()
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
if gpu >= 0:
chainer.cuda.get_device(gpu).use()
model.to_gpu(gpu)
train_x = chainer.cuda.to_gpu(train_x)
train_y = chainer.cuda.to_gpu(train_y)
# 学習
epoch_num = 5
batch_size = 1000
N = train_x.shape[0]
st = datetime.datetime.now()
for epoch in range(epoch_num):
# mini-batch
perm = np.random.permutation(N)
total_loss = 0
total_accuracy = 0
for i in range(0, N, batch_size):
x = train_x[perm[i:i+batch_size]]
t = train_y[perm[i:i+batch_size]]
model.reset()
loss, accuracy = model(x=x, t=t, train=True)
loss.backward()
loss.unchain_backward()
total_loss += loss.data
total_accuracy += accuracy.data
optimizer.update()
ed = datetime.datetime.now()
print("epoch:\t{}\ttotal loss:\t{}\tmean accuracy:\t{}\ttime:\t{}".format(epoch+1, total_loss, total_accuracy/(N/batch_size), ed-st))
st = datetime.datetime.now()epoch: 1 total loss: 103.07084 mean accuracy: 0.6566249 time: 0:00:00.707081
epoch: 2 total loss: 94.620056 mean accuracy: 0.7714464 time: 0:00:00.673655
epoch: 3 total loss: 93.4981 mean accuracy: 0.7904821 time: 0:00:00.678233
epoch: 4 total loss: 85.87946 mean accuracy: 0.9309107 time: 0:00:00.706425
epoch: 5 total loss: 83.2471 mean accuracy: 0.9762682 time: 0:00:00.683051混合行列を確認した結果がこちらです。
model.to_cpu()
preds = model(valid_x, train=False)
cm = metrics.confusion_matrix(preds, valid_y)
plt.figure(figsize=(10,8))
sns.heatmap(cm, annot=True, fmt='d')
plt.show()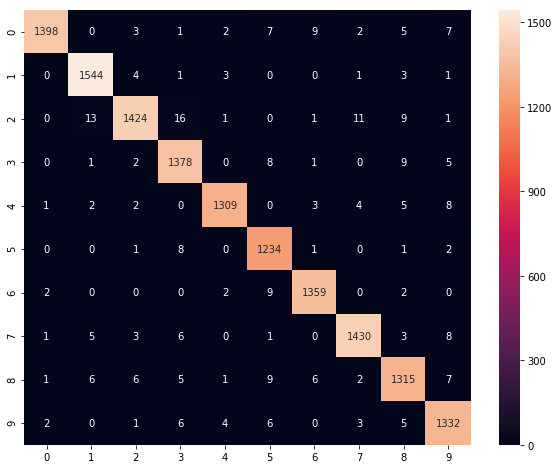
何枚か予測させてみた結果がこちらです。
indices = np.random.choice(len(valid_x), 30)
for i, idx in enumerate(indices):
if i%10 == 0:
fig, axs = plt.subplots(ncols=10, figsize=(15,1))
x = valid_x[idx]
y = valid_y[idx]
x_img = x.reshape(28, 28)
x = x[np.newaxis]
pred = model(x, train=False)[0]
axs[i%10].imshow(x_img, cmap='gray')
title = 'y: {}'.format(y) + '\n' + 'pred: {}'.format(pred)
axs[i%10].set_title(title)
axs[i%10].axis('off')
plt.show()
Classifierクラス・Trainerクラスを用いると以下のように書けます。
モデルクラスが順伝播の役割だけにシンプル化されていて、学習部分もとてもスッキリ書けます。
import numpy as np
import matplotlib
import matplotlib.pylab as plt
import seaborn as sns
from sklearn import model_selection, metrics
import chainer
import chainer.functions as F
import chainer.links as L
from chainer.training import extensions
# train data size : validation data size= 8 : 2
train_x, valid_x, train_y, valid_y = model_selection.train_test_split(mnist['data'], mnist['target'], test_size=0.2)
train_dataset = chainer.datasets.tuple_dataset.TupleDataset(train_x, train_y)
valid_dataset = chainer.datasets.tuple_dataset.TupleDataset(valid_x, valid_y)
# モデルクラス定義
class CNN(chainer.Chain):
def __init__(self):
super(CNN, self).__init__(
conv1 = L.Convolution2D(1, 20, ksize=5),
conv2 = L.Convolution2D(20, 50, ksize=5),
fc1 = L.Linear(None, 500),
fc2 = L.Linear(500, 500),
fc3 = L.Linear(500, 10)
)
def __call__(self, x):
h = F.max_pooling_2d(F.relu(self.conv1(x)), 2)
h = F.max_pooling_2d(F.relu(self.conv2(h)), 2)
h = self.fc1(h)
h = self.fc2(h)
y = self.fc3(h)
return y
# モデルとオプティマイザの準備
gpu = 0
model = L.Classifier(CNN())
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
if gpu >= 0:
chainer.cuda.get_device(gpu).use()
model.to_gpu(gpu)
# 学習
epoch_num = 10
batch_size = 1000
train_iter = chainer.iterators.SerialIterator(train_dataset, batch_size)
test_iter = chainer.iterators.SerialIterator(valid_dataset, batch_size, repeat=False, shuffle=False)
updater = chainer.training.StandardUpdater(train_iter, optimizer, device=gpu)
trainer = chainer.training.Trainer(updater, (epoch_num, 'epoch'), out='result')
trainer.extend(extensions.Evaluator(test_iter, model, device=gpu))
trainer.extend(extensions.LogReport(trigger=(1, 'epoch')))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy', 'elapsed_time']))
trainer.run()epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
1 0.410563 0.106101 0.873232 0.968071 13.8441
2 0.0775864 0.0748249 0.976143 0.976572 14.5781
3 0.0493338 0.0472499 0.985 0.985857 15.3067
4 0.0381874 0.0457631 0.987768 0.986286 16.0328
5 0.0298464 0.0450175 0.990696 0.987071 16.7709
6 0.0265287 0.0429706 0.991482 0.986786 17.513
7 0.0200595 0.0417418 0.993822 0.986857 18.2376
8 0.0140155 0.0386183 0.995768 0.988571 18.9775
9 0.0122673 0.0397485 0.996197 0.989143 19.7192
10 0.0107453 0.0427487 0.996589 0.988429 20.4545 混合行列を確認した結果がこちらです。
model.to_cpu()
with chainer.using_config('train', False):
preds = F.argmax(F.softmax(model.predictor(valid_x), axis=1), axis=1).data.squeeze()
cm = metrics.confusion_matrix(preds, valid_y)
plt.figure(figsize=(10,8))
sns.heatmap(cm, annot=True, fmt='d')
plt.show()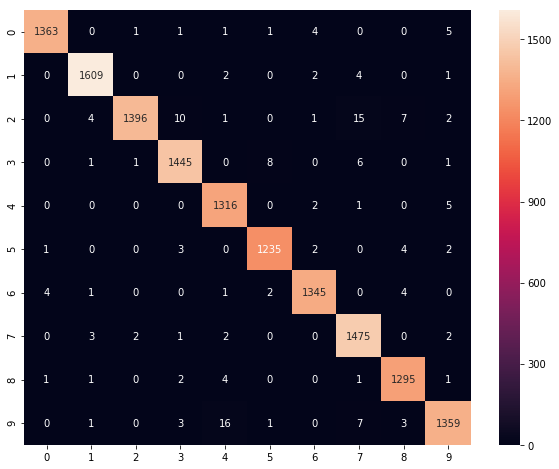
何枚か予測させてみた結果がこちらです。
indices = np.random.choice(len(valid_x), 30)
for i, idx in enumerate(indices):
if i%10 == 0:
fig, axs = plt.subplots(ncols=10, figsize=(15,1))
x = valid_x[idx]
y = valid_y[idx]
x_img = x.reshape(28, 28)
x = x[np.newaxis]
with chainer.using_config('train', False):
pred = F.argmax(F.softmax(model.predictor(x), axis=1), axis=1).data.squeeze()
axs[i%10].imshow(x_img, cmap='gray')
title = 'y: {}'.format(y) + '\n' + 'pred: {}'.format(pred)
axs[i%10].set_title(title)
axs[i%10].axis('off')
plt.show()
PyTorchによるCNNの実装
PyTorchの場合は以下の通りになります。
PyTorchはChainerにインスパイヤされて開発されているので、Chainerの生の書き方ととても似ています。
import sys
import numpy as np
import matplotlib.pylab as plt
import seaborn as sns
from sklearn import model_selection, metrics
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.autograd import Variable
from tqdm import tqdm
gpu = 0
device = torch.device("cuda:{}".format(gpu) if torch.cuda.is_available() else "cpu")
# train data size : validation data size= 8 : 2
train_x, valid_x, train_y, valid_y = model_selection.train_test_split(mnist['data'], mnist['target'], test_size=0.2)
# DataLoader化
batch_size = 1000
train = torch.utils.data.TensorDataset(torch.from_numpy(train_x), torch.from_numpy(train_y))
train_loader = torch.utils.data.DataLoader(train, batch_size=batch_size, shuffle=True)
valid = torch.utils.data.TensorDataset(torch.from_numpy(valid_x), torch.from_numpy(valid_y))
valid_loader = torch.utils.data.DataLoader(valid, batch_size=batch_size)
# モデルクラス定義
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 画像を畳み込みを行うまで
self.head = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=20, kernel_size=(5, 5), stride=1, padding=0),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=20, out_channels=50, kernel_size=(5, 5), stride=1, padding=0),
nn.MaxPool2d(kernel_size=2)
)
# 畳み込みで得られたベクトルを出力層に順伝播させるまで
self.tail = nn.Sequential(
nn.Linear(50*4*4, 500),
nn.ReLU(),
nn.Linear(500, 500),
nn.ReLU(),
nn.Linear(500, 10)
)
def __call__(self, x):
h = self.head(x)
h = h.view(-1, 50*4*4)
y = self.tail(h)
return y
# モデルとオプティマイザの準備
model = CNN()
if torch.cuda.is_available():
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
# 学習
def forward(data_loader, train=True):
running_loss = 0
correct = 0
total = 0
for batch_idx, (xs, ys) in enumerate(data_loader):
if torch.cuda.is_available():
xs, ys = xs.to(device), ys.to(device).long()
preds = model(xs)
if train:
optimizer.zero_grad()
loss = criterion(preds, ys)
running_loss += loss.item()
loss.backward()
optimizer.step()
else:
loss = criterion(preds, ys)
running_loss += loss.item()
_, pred_labels = torch.max(preds.data, 1)
correct += (pred_labels == ys.data).sum().item()
total += ys.size(0)
loss = running_loss / len(data_loader)
acc = correct / total
return loss, acc
epoch_num = 5
for epoch in tqdm(range(epoch_num), file=sys.stdout):
train_loss, train_acc = forward(train_loader)
val_loss, val_acc = forward(valid_loader, train=False)
if (epoch+1) % 1 == 0:
tqdm.write('epoch:\t{}\ttrain loss:\t{:.5f}\ttrain acc:\t{:.5f}\tval loss:\t{:.5f}\tval acc:\t{:.5f}'.format(
epoch+1, train_loss, train_acc, val_loss, val_acc)
)epoch: 1 train loss: 0.62843 train acc: 0.82121 val loss: 0.18639 val acc: 0.94286
epoch: 2 train loss: 0.13478 train acc: 0.95946 val loss: 0.08982 val acc: 0.97221
epoch: 3 train loss: 0.07862 train acc: 0.97600 val loss: 0.06848 val acc: 0.97850
epoch: 4 train loss: 0.05616 train acc: 0.98261 val loss: 0.06634 val acc: 0.97800
epoch: 5 train loss: 0.04141 train acc: 0.98739 val loss: 0.04751 val acc: 0.98507
100%|██████████| 5/5 [00:06<00:00, 1.25s/it]混合行列を確認した結果がこちらです。
model.cpu()
loader = torch.utils.data.DataLoader(valid, batch_size=len(valid_x))
for i, (x, y) in enumerate(loader):
preds = model(x)
_, pred_labels = torch.max(preds.data, 1)
cm = metrics.confusion_matrix(pred_labels, valid_y)
plt.figure(figsize=(10,8))
sns.heatmap(cm, annot=True, fmt='d')
plt.show()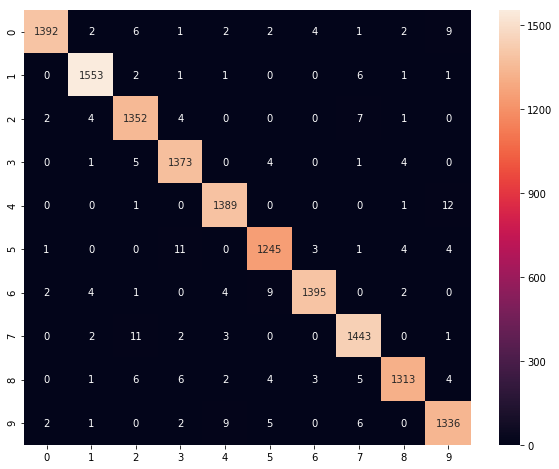
何枚か予測させてみた結果がこちらです。
indices = np.random.choice(len(valid_x), 30)
for i, idx in enumerate(indices):
if i%10 == 0:
fig, axs = plt.subplots(ncols=10, figsize=(15,1))
x = valid_x[idx]
y = valid_y[idx]
x_img = x.reshape(28, 28)
x = x[np.newaxis]
x = torch.from_numpy(x)
pred = model(x)
pred = pred.data.numpy()
p = np.argmax(pred, axis=1)[0]
axs[i%10].imshow(x_img, cmap='gray')
title = 'y: {}'.format(y) + '\n' + 'pred: {}'.format(p)
axs[i%10].set_title(title)
axs[i%10].axis('off')
plt.show()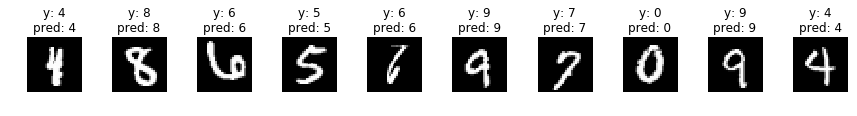


TensorFlowによるCNNの実装
次にTensorFlowによる書き方です。
TensorFlowも自分でネットワークを作る書き方と、kerasを使ってある程度スッキリとした書き方があるので、今回の記事では両方のパターンを作ってみます。
自身でネットワークを定義する書き方は以下の通りです。
import sys
import numpy as np
import matplotlib
import matplotlib.pylab as plt
import seaborn as sns
from sklearn import model_selection, metrics
import tensorflow as tf
from tqdm import tqdm
# train data size : validation data size= 8 : 2
train_x, valid_x, train_y, valid_y = model_selection.train_test_split(mnist['data'], mnist['target'], test_size=0.2)
# ラベルはone-hotベクトルに変換する
train_y = np.eye(np.max(train_y)+1)[train_y]
valid_y = np.eye(np.max(valid_y)+1)[valid_y]
# ネットワークの定義
# プレースホルダー
x_ = tf.placeholder(tf.float32, shape=(None, 28, 28, 1))
y_ = tf.placeholder(tf.float32, shape=(None, 10))
# 畳み込み層1
conv1_features = 20 # 畳み込み層1の出力次元数
max_pool_size1 = 2 # 畳み込み層1のマックスプーリングサイズ
conv1_w = tf.Variable(tf.truncated_normal([5, 5, 1, conv1_features], stddev=0.1), dtype=tf.float32) # 畳み込み層1の重み
conv1_b = tf.Variable(tf.constant(0.1, shape=[conv1_features]), dtype=tf.float32) # 畳み込み層1のバイアス
conv1_c2 = tf.nn.conv2d(x_, conv1_w, strides=[1, 1, 1, 1], padding="SAME") # 畳み込み層1-畳み込み
conv1_relu = tf.nn.relu(conv1_c2+conv1_b) # 畳み込み層1-ReLU
conv1_mp = tf.nn.max_pool(conv1_relu, ksize=[1, max_pool_size1, max_pool_size1, 1], strides=[1, max_pool_size1, max_pool_size1, 1], padding="SAME") # 畳み込み層1-マックスプーリング
# 畳み込み層2
conv2_features = 50 # 畳み込み層2の出力次元数
max_pool_size2 = 2 # 畳み込み層2のマックスプーリングのサイズ
conv2_w = tf.Variable(tf.truncated_normal([5, 5, conv1_features, conv2_features], stddev=0.1), dtype=tf.float32) # 畳み込み層2の重み
conv2_b = tf.Variable(tf.constant(0.1, shape=[conv2_features]), dtype=tf.float32) # 畳み込み層2のバイアス
conv2_c2 = tf.nn.conv2d(conv1_mp, conv2_w, strides=[1, 1, 1, 1], padding="SAME") # 畳み込み層2-畳み込み
conv2_relu = tf.nn.relu(conv2_c2+conv2_b) # 畳み込み層2-ReLU
conv2_mp = tf.nn.max_pool(conv2_relu, ksize=[1, max_pool_size2, max_pool_size2, 1], strides=[1, max_pool_size2, max_pool_size2, 1], padding="SAME") # 畳み込み層2-マックスプーリング
# 全結合層1
result_w = x_.shape[1] // (max_pool_size1*max_pool_size2)
result_h = x_.shape[2] // (max_pool_size1*max_pool_size2)
fc_input_size = result_w * result_h * conv2_features # 畳み込んだ結果、全結合層に入力する次元数
fc_features = 500 # 全結合層の出力次元数(隠れ層の次元数)
s = conv2_mp.get_shape().as_list() # [None, result_w, result_h, conv2_features]
conv_result = tf.reshape(conv2_mp, [-1, s[1]*s[2]*s[3]]) # 畳み込みの結果を1*N層に変換
fc1_w = tf.Variable(tf.truncated_normal([fc_input_size.value, fc_features], stddev=0.1), dtype=tf.float32) # 重み
fc1_b = tf.Variable(tf.constant(0.1, shape=[fc_features]), dtype=tf.float32) # バイアス
fc1 = tf.nn.relu(tf.matmul(conv_result, fc1_w)+fc1_b) # 全結合層1
# 全結合層2
fc2_w = tf.Variable(tf.truncated_normal([fc_features, fc_features], stddev=0.1), dtype=tf.float32) # 重み
fc2_b = tf.Variable(tf.constant(0.1, shape=[fc_features]), dtype=tf.float32) # バイアス
fc2 = tf.nn.relu(tf.matmul(fc1, fc2_w)+fc2_b) # 全結合層2
# 全結合層3
fc3_w = tf.Variable(tf.truncated_normal([fc_features, 10], stddev=0.1), dtype=tf.float32) # 重み
fc3_b = tf.Variable(tf.constant(0.1, shape=[10]), dtype=tf.float32) # バイアス
pred = tf.nn.softmax(tf.matmul(fc2, fc3_w)+fc3_b)
#y = tf.nn.softmax(tf.matmul(x, W) + b)
# クロスエントロピー誤差
#cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_))
cross_entropy = -tf.reduce_sum(y_*tf.log(pred))
# 勾配法
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 正解率の計算
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 学習
epoch_num = 5
batch_size = 1000
train_size = len(train_x)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
for epoch in tqdm(range(epoch_num), file=sys.stdout):
perm = np.random.permutation(train_size)
total_loss = 0
for i in range(0, train_size, batch_size):
batch_x = train_x[perm[i:i+batch_size]]
batch_y = train_y[perm[i:i+batch_size]]
train_step.run(feed_dict={x_: batch_x, y_: batch_y})
total_loss += cross_entropy.eval(feed_dict={x_:batch_x, y_: batch_y})
if (epoch+1)%1 == 0:
train_accuracy = accuracy.eval(feed_dict={x_: train_x, y_: train_y})
test_accuracy = accuracy.eval(feed_dict={x_: valid_x, y_: valid_y})
tqdm.write('epoch:\t{}\tloss:\t{}\taccuracy:\t{}\ttest accuracy:\t{}'.format(epoch+1, total_loss, train_accuracy, test_accuracy))epoch: 1 loss: 87826.048828125 accuracy: 0.833392858505249 test accuracy: 0.8343571424484253
epoch: 2 loss: 22228.538848876953 accuracy: 0.9141964316368103 test accuracy: 0.9131428599357605
epoch: 3 loss: 13720.878723144531 accuracy: 0.9390714168548584 test accuracy: 0.9347142577171326
epoch: 4 loss: 10438.166870117188 accuracy: 0.9506964087486267 test accuracy: 0.9468571543693542
epoch: 5 loss: 8523.885612487793 accuracy: 0.960107147693634 test accuracy: 0.9558571577072144
100%|██████████| 5/5 [00:08<00:00, 1.69s/it]混合行列を確認した結果がこちらです。
preds = np.argmax(pred.eval(feed_dict={x_: valid_x}), axis=1)
cm = metrics.confusion_matrix(preds, np.argmax(valid_y, axis=1))
plt.figure(figsize=(10,8))
sns.heatmap(cm, annot=True, fmt='d')
plt.show()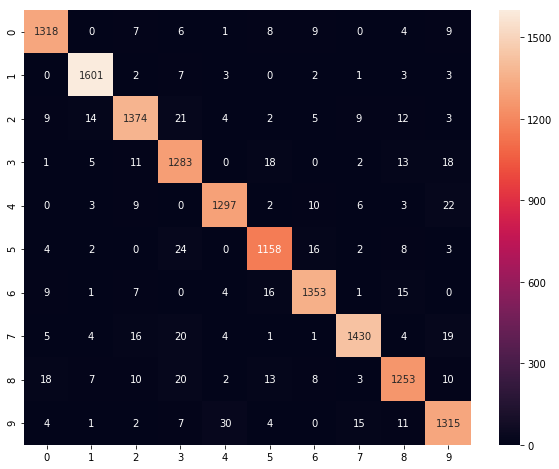
何枚か予測させてみた結果がこちらです。
indices = np.random.choice(len(valid_x), 30)
for i, idx in enumerate(indices):
if i%10 == 0:
fig, axs = plt.subplots(ncols=10, figsize=(15,1))
x = valid_x[idx]
y = np.argmax(valid_y, axis=1)[idx]
x_img = x.reshape(28, 28)
x = x[np.newaxis]
p = np.argmax(pred.eval(feed_dict={x_: x}), axis=1)[0]
axs[i%10].imshow(x_img, cmap='gray')
title = 'y: {}'.format(y) + '\n' + 'pred: {}'.format(p)
axs[i%10].set_title(title)
axs[i%10].axis('off')
plt.show()

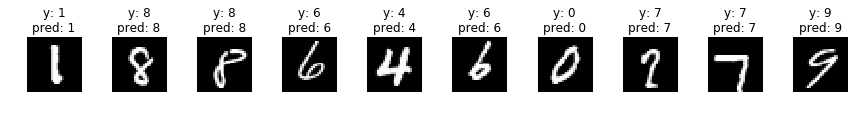
次にkerasを使った書き方が以下の通りです。
だいぶスッキリとして書けます。
import sys
import numpy as np
import matplotlib
import matplotlib.pylab as plt
import seaborn as sns
from sklearn import model_selection, metrics
import tensorflow as tf
from tqdm import tqdm
# train data size : validation data size= 8 : 2
train_x, valid_x, train_y, valid_y = model_selection.train_test_split(mnist['data'], mnist['target'], test_size=0.2)
# ラベルはone-hotベクトルに変換する
train_y = np.eye(np.max(train_y)+1)[train_y]
valid_y = np.eye(np.max(valid_y)+1)[valid_y]
epoch_num = 1
batch_size = 1000
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(20, (5, 5), activation=tf.nn.relu),
tf.keras.layers.Conv2D(50, (5, 5), activation=tf.nn.relu),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(500, activation=tf.nn.relu),
tf.keras.layers.Dense(500, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=tf.train.AdamOptimizer(),
loss=tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy]
)
model.fit(train_x, train_y, epochs=epoch_num, batch_size=batch_size, validation_data=(valid_x, valid_y))Train on 56000 samples, validate on 14000 samples
Epoch 1/1
56000/56000 [==============================] - 2s 29us/step - loss: 0.4044 - categorical_accuracy: 0.8761 - val_loss: 0.0894 - val_categorical_accuracy: 0.9734混合行列を確認した結果がこちらです。
preds = np.argmax(model.predict(valid_x), axis=1)
cm = metrics.confusion_matrix(preds, np.argmax(valid_y, axis=1))
plt.figure(figsize=(10,8))
sns.heatmap(cm, annot=True, fmt='d')
plt.show()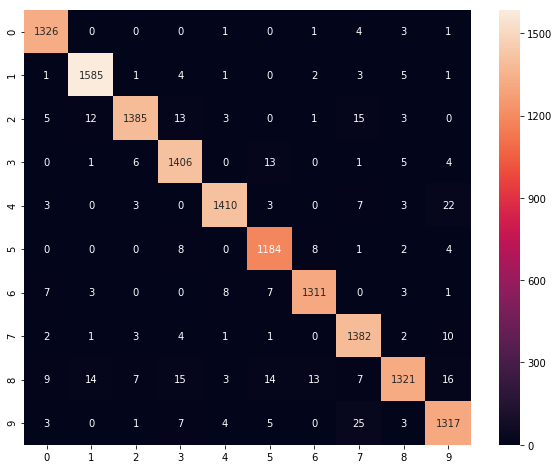
何枚か予測させてみた結果がこちらです。
indices = np.random.choice(len(valid_x), 30)
for i, idx in enumerate(indices):
if i%10 == 0:
fig, axs = plt.subplots(ncols=10, figsize=(15,1))
x = valid_x[idx]
y = np.argmax(valid_y, axis=1)[idx]
x_img = x.reshape(28, 28)
x = x[np.newaxis]
p = np.argmax(model.predict(x), axis=1)[0]
axs[i%10].imshow(x_img, cmap='gray')
title = 'y: {}'.format(y) + '\n' + 'pred: {}'.format(p)
axs[i%10].set_title(title)
axs[i%10].axis('off')
plt.show()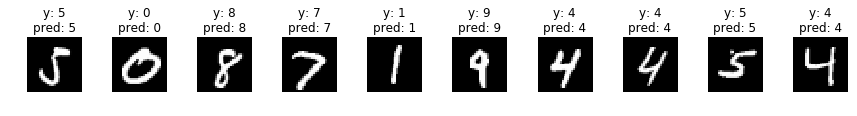
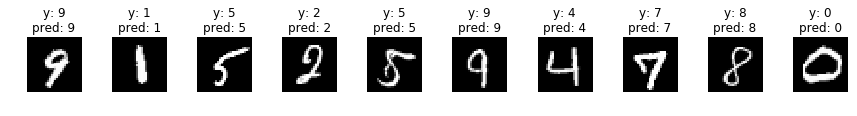
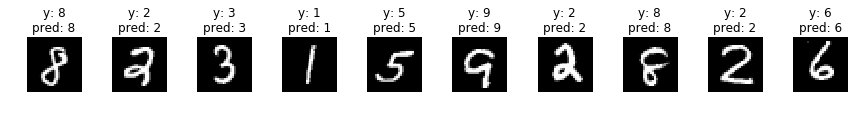
まとめ
この記事では、Chainer、PyTorch、TensorFlowを使った簡単なCNNの実装方法について学びました。
Chainerでは、ネットワークをクラスとして定義し、各層を関数として組み立てる方法を紹介しました。
特にClassifierクラスやTrainerクラスなどの便利な関数によるシンプルな記法により、柔軟でカスタマイズ性の高いモデル構築が可能であるという特長があります。
PyTorchでは、Chainerと同様にクラスを使用してCNNモデルを定義する手法を解説しました。
そしてTensorFlowを使った場合は、ネットワークを自ら定義する方法と、KerasのAPIを使用してシンプルに構築する方法を学びました。
Kerasの高い抽象化レベルにより、簡潔かつ効率的な記述が可能であり、深層学習初心者にもおすすめです。
深層学習の世界は広く、さらに高度なモデルやテクニックが存在しますが、これらの基本的な知識を踏まえることで、より洗練されたモデルを追求していくことができるでしょう。
引き続き学習を続け、さまざまな応用にチャレンジしてみてください。