
ベイズ推論では、機械学習や統計学における従来の確率的手法に加え、不確実性を取り入れることで、より柔軟なモデル構築が可能となります。
ベイズニューラルネットワークは、ベイズ推論と同じように、確率的なモデルとして不確実性を考慮したニューラルネットワークの一種です。
今回は、ベイズ推論とベイズニューラルネットワークの基本的な概念から、実際のPythonコードを用いた具体的な実装例までご紹介します。
実装にあたっては、最近勉強中のEdwardというライブラリを使ってベイズニューラルネットワークを実装してみます。
Edwardはベイズニューラルネットワークも実装可能なライブラリ(詳細は後述)ですが、実は公式ページにはわずかに参考程度にしか触れられていません。
そこで独自の理解を元に実装を試みたところうまく学習してくれましたので、ここで共有したいと思います。
ベイズ推論やベイズニューラルネットワークに興味がある方や、実践的な手法を身につけたい方にとって、この記事が一助となれば幸いです。
ベイズ推論とベイズニューラルネットワーク
まずはベイズ推論の基本的な考え方について触れます。
ベイズ推論では、観測データの集合\(\mathcal{D}\)と未知のパラメータ\(\theta\)に関して、モデル\(p(\mathcal{D},\theta)=p(\mathcal{D}|\theta)p(\theta)\)を構築し、事後分布
\(p(\theta|\mathcal{D})=\displaystyle\frac{p(\mathcal{D}|\theta)p(\theta)}{p(\mathcal{D})}=\displaystyle\frac{p(\mathcal{D}|\theta)p(\theta)}{{\int}p(\mathcal{D}|\theta)p(\theta)d\theta}\)
を解析的または近似的に求めます。
モデルの構築において自然共益事前分布を仮定すれば、事後分布は解析的に求まりますが、そうでない場合は\({\int}p(\mathcal{D}|\theta)p(\theta)d\theta\)の計算がとても困難なものになるため、代わりにマルコフ連鎖モンテカルロ法や変分推論を使って近似的に事後分布を求めます。
マルコフ連鎖モンテカルロ法(Markov Chain Monte Carlo: MCMC)では、\(\theta_i{\sim}p(\theta|\mathcal{D})\)を大量に得て(サンプリング)、平均や分散を求めてみたりプロットしてみたりして、分布の外観を把握します。
変分推論(Variational Inference)または変分近似(Variational Approximation)では、解析しやすい分布\(q(\theta;\eta)\)を考え、\(p(\theta|\mathcal{D}){\approx}q(\theta;\eta)\)と近似します。
言い換えると、目的関数\(\arg\min_{\eta}KL(q(\theta;\eta){\parallel}p(\theta|\mathcal{D}))\)の最小化問題を解くことになります。
この辺りの参考になる書籍としては、例えば以下が参考になるでしょう。
上記書籍はサンプルコードもGitHubに上がっています。(ただしJuliaですが笑)
以上を踏まえて、次にベイズニューラルネットワークの考え方について触れていきます。
ベイズニューラルネットワークでは、ニューラルネットワークのパラメータ(重みとバイアス)\({\boldsymbol w}\)がある確率分布に従うと仮定し、その事後分布をベイズ推論により求めます。
\({\boldsymbol w}{\sim}N({\boldsymbol 0},{\boldsymbol I})\)
\(p(y|{\boldsymbol x},{\boldsymbol w})=\text{Categorical}\Bigl(\displaystyle\frac{\exp(f({\boldsymbol x},{\boldsymbol w}))}{\sum\exp(f({\boldsymbol x},{\boldsymbol w}))}\Bigr)\)
\(f(\cdot) : \text{活性化関数など}\)
ニューラルネットワークにベイズを適用する話は歴史的には古くからあったようで、メリットやデメリットとしては下記のように、やはりベイズ推論で一般的によく言われることと同等のことが言えるようです。
- メリット: 少ない学習データで学習が可能、過学習が抑えられる(というより過学習という概念がない)
- デメリット: 計算量が多い、再現性がない場合がある
Edwardについて
Edwardはベイズ統計などで扱う確率モデルを実装できるライブラリです。
PyStanやPyMCも同様のライブラリです。
- Edward: http://edwardlib.org/
このライブラリの特徴としては下記などが挙げられます。
- 2016年より開発されている確率的プログラミングのPythonライブラリ
- Dustin Tran氏(Open AI)が開発をリード
- LDAで有名なコロンビア大学のBlei先生の研究室で開発
- 計算にTensorFlowを用いている
- 計算速度がStanやPyMC3よりも速い
- GPUによる高速化が可能
- TensorBoardによる可視化も可能
ベイズ統計はもちろん実装可能ですが、特にPyStanやPyMCと異なるポイントとして、深層学習などに対するベイズの適用実装も可能なライブラリです。
この辺りについては公式にチュートリアルに色々な参考例があり、例えば、下記のようなアルゴリズムの実装が可能のようです。
- Bayesian linear regression
- Automated Transformations
- Linear Mixed Effects Models
- Mixture Density Networks
- Probabilistic Decoder
- Inference Networks
- Bayesian Neural Network
- Probabilistic PCA
また、現段階において、今後このライブラリはTensorFlowにマージされる予定のようです。
ちなみに余談ですが、この「Edward」という名前は、Box-Cox変換やLjung-Box検定で知られている統計学者George Edward Pelham Boxから取っているようです。
この章で少し使い方も見てみましょう。
EdwardはバックエンドにTensorFlowを用いており、使い勝手もTensorFlowと同様に、計算グラフを作成、セッションを宣言、値をフローという流れで使用します。
import numpy as np
import tensorflow as tf
import edward as ed
# 正規分布の値を生成
from edward.models import Normal
x = Normal(loc=0.0, scale=1.0)
sess = tf.Session() # or ed.get_session()
sample_x = sess.run(x)
print(sample_x)0.0919603テンソルで処理できるため、以下のように、一気に値をベクトル生成することも可能です。
# テンソルで生成可能
from edward.models import Normal
N = 10
x = Normal(loc=tf.zeros([N]), scale=tf.ones([N]))
sess = tf.Session() # or ed.get_session()
samples_x = sess.run(x)
print(samples_x)[-0.36161533 -0.67601579 -1.04770219 -0.70425886 -0.62890649 0.3660461
0.31013817 -0.64070946 0.26981813 0.24564922]パラメータの事前分布を指定する場合も、以下のようにPythonっぽく書けます。
この辺りはStanの書き方よりもPyMCの書き方に少し似ています。
# 正規分布の平均が正規分布に従うモデルの値を生成
from edward.models import Normal
mu = Normal(loc=0.0, scale=1.0)
x = Normal(loc=mu, scale=1.0)
sess = tf.Session()
sample_mu, sample_x = sess.run([mu, x])
print(sample_mu)
print(sample_x)-0.622465
1.9574もちろん計算グラフなので、プレースホルダーを用いて、値を供給して生成することもできます。
# 変数に値を供給して値を生成
from edward.models import Normal
mu_ = tf.placeholder(tf.float32)
x = Normal(loc=mu_, scale=1.0, sample_shape=10)
sess = tf.Session()
mu, samples_x = sess.run([mu_, x], feed_dict={mu_: 50.0})
print(mu)
print(samples_x)50.0
[ 49.63046646 47.55083084 49.45754623 49.77397919 51.31248474
48.98104858 52.11248398 50.42101669 50.32041931 50.07067108]パラメータの事後分布を求める場合には、変分推論かMCMC法が使えます。
変分推論の場合:
# 正規分布のパラメータの事後分布を求める(変分推論)
from edward.models import Normal
N = 30
x_train = np.random.randint(10, 20, N) # 10〜20の観測値がN個
mu = Normal(loc=0.0, scale=1.0)
x = Normal(loc=mu, scale=1.0, sample_shape=N)
qmu = Normal(loc=tf.Variable(0.0), scale=1.0)
inference = ed.KLqp({mu: qmu}, data={x: x_train})
inference.run(n_iter=1000)
samples = qmu.sample(100).eval()
print(samples.mean())1000/1000 [100%] ██████████████████████████████ Elapsed: 0s | Loss: 278.396
14.7295MCMCの場合:
# 正規分布のパラメータの事後分布を求める(MCMC)
from edward.models import Empirical
N = 30
x_train = np.random.randint(10, 20, N) # 10〜20の観測値がN個
T = 1000
mu = Normal(loc=0.0, scale=1.0)
x = Normal(loc=mu, scale=1.0, sample_shape=N)
qmu = Empirical(tf.Variable(tf.zeros(T)))
inference = ed.HMC({mu: qmu}, {x: x_train})
inference.run(n_iter=T)
samples = qmu.sample(100).eval()
print(samples.mean())1000/1000 [100%] ██████████████████████████████ Elapsed: 1s | Acceptance Rate: 0.915
14.7666ベイズニューラルネットワークによる毒キノコ分類モデル
それでは、実際に何かしらの問題に対してベイズニューラルネットワークを実装する例を見てみようと思います。
試しに動かしてみたく問題は何でも良かったので、今回は表題の通り、Kaggleに下記毒キノコの分類用のデータセットがあって面白そうでしたので使ってみましょう。
食用キノコか毒キノコかがラベル付けされているデータセットです。mushrooms.csvを見てみると下記のようになっています。
data = pd.read_csv('../input/mushrooms.csv')
data.head()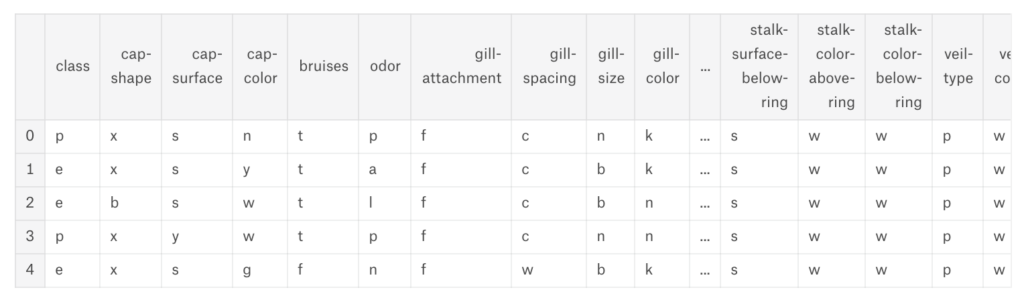
一番左のclass列がpが毒(poisson)、eが食用(eatable)となっており、その他、傘の形、傘の表面、傘の色、匂いなどが格納されている、面白いデータセットです。
カラムの値はすべてオブジェクト型になっているようですので、ダミー変数化しておきます。
カラムが目的変数分の2カラム(p,e)を引いて、117カラムあるようなので、これを全て説明変数ベクトルとして与えて、ニューラルネットワークを学習・予測をさせてみます。
せっかくなので、今回は普通の隠れ層のない単純なニューラルネットワークとベイズニューラルネットワークの両方を実装してみて、実装の違いを確認してみましょう。
まずは教師データの準備です。
上記のように、class_pとclass_eはラベルデータとして、残りを入力データとします。
data2 = pd.get_dummies(data)
data2.shape # (8124, 119)
data_x = data2.loc[:, 'cap-shape_b':].as_matrix().astype(np.float32)
data_y = data2.loc[:, :'class_p'].as_matrix().astype(np.float32)
N = 7000
train_x, test_x = data_x[:N], data_x[N:]
train_y, test_y = data_y[:N], data_y[N:]
in_size = train_x.shape[1]
out_size = train_y.shape[1]
EPOCH_NUM = 5
BATCH_SIZE = 1000
# for bayesian neural network
train_y2 = np.argmax(train_y, axis=1)
test_y2 = np.argmax(test_y, axis=1)隠れ層のない単純なニューラルネットワークから作成してみます。
TensorFlowでモデルを構築して学習・予測をさせてみます。
import sys
from tqdm import tqdm
import tensorflow as tf
x_ = tf.placeholder(tf.float32, shape=[None, in_size])
y_ = tf.placeholder(tf.float32, shape=[None, out_size])
w = tf.Variable(tf.truncated_normal([in_size, out_size], stddev=0.1), dtype=tf.float32)
b = tf.Variable(tf.constant(0.1, shape=[out_size]), dtype=tf.float32)
y_pre = tf.matmul(x_, w) + b
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_pre))
train_step = tf.train.AdamOptimizer().minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for epoch in tqdm(range(EPOCH_NUM), file=sys.stdout):
perm = np.random.permutation(N)
for i in range(0, N, BATCH_SIZE):
batch_x = train_x[perm[i:i+BATCH_SIZE]]
batch_y = train_y[perm[i:i+BATCH_SIZE]]
train_step.run(session=sess, feed_dict={x_: batch_x, y_: batch_y})
acc = accuracy.eval(session=sess, feed_dict={x_: train_x, y_: train_y})
test_acc = accuracy.eval(session=sess, feed_dict={x_: test_x, y_: test_y})
if (epoch+1) % 1 == 0:
tqdm.write('epoch:\t{}\taccuracy:\t{}\tvalidation accuracy:\t{}'.format(epoch+1, acc, test_acc))epoch: 1 accuracy: 0.583142876625061 validation accuracy: 0.7580071091651917
epoch: 2 accuracy: 0.6795714497566223 validation accuracy: 0.8300711512565613
epoch: 3 accuracy: 0.7567142844200134 validation accuracy: 0.8923487663269043
epoch: 4 accuracy: 0.8140000104904175 validation accuracy: 0.9234875440597534
epoch: 5 accuracy: 0.8548571467399597 validation accuracy: 0.9466192126274109
100%|██████████| 5/5 [00:00-00:00, 42.09it/s]問題なく学習できているようです。
次にベイズニューラルネットワークをEdwardで実装して学習させてみます。
import edward as ed
from edward.models import Normal, Categorical
x_ = tf.placeholder(tf.float32, shape=(None, in_size))
y_ = tf.placeholder(tf.int32, shape=(BATCH_SIZE))
w = Normal(loc=tf.zeros([in_size, out_size]), scale=tf.ones([in_size, out_size]))
b = Normal(loc=tf.zeros([out_size]), scale=tf.ones([out_size]))
y_pre = Categorical(tf.matmul(x_, w) + b)
qw = Normal(loc=tf.Variable(tf.random_normal([in_size, out_size])), scale=tf.Variable(tf.random_normal([in_size, out_size])))
qb = Normal(loc=tf.Variable(tf.random_normal([out_size])), scale=tf.Variable(tf.random_normal([out_size])))
y = Categorical(tf.matmul(x_, qw) + qb)
inference = ed.KLqp({w: qw, b: qb}, data={y_pre: y_})
inference.initialize()
sess = tf.Session()
sess.run(tf.global_variables_initializer())
with sess:
samples_num = 100
for epoch in tqdm(range(EPOCH_NUM), file=sys.stdout):
perm = np.random.permutation(N)
for i in range(0, N, BATCH_SIZE):
batch_x = train_x[perm[i:i+BATCH_SIZE]]
batch_y = train_y2[perm[i:i+BATCH_SIZE]]
inference.update(feed_dict={x_: batch_x, y_: batch_y})
y_samples = y.sample(samples_num).eval(feed_dict={x_: train_x})
acc = (np.round(y_samples.sum(axis=0) / samples_num) == train_y2).mean()
y_samples = y.sample(samples_num).eval(feed_dict={x_: test_x})
test_acc = (np.round(y_samples.sum(axis=0) / samples_num) == test_y2).mean()
if (epoch+1) % 1 == 0:
tqdm.write('epoch:\t{}\taccuracy:\t{}\tvalidation accuracy:\t{}'.format(epoch+1, acc, test_acc))epoch: 1 accuracy: 0.7514285714285714 validation accuracy: 0.9519572953736655
epoch: 2 accuracy: 0.8384285714285714 validation accuracy: 0.9145907473309609
epoch: 3 accuracy: 0.9528571428571428 validation accuracy: 0.8647686832740213
epoch: 4 accuracy: 0.9382857142857143 validation accuracy: 0.8469750889679716
epoch: 5 accuracy: 0.895 validation accuracy: 0.9741992882562278
100%|██████████| 5/5 [00:00<00:00, 9.69it/s]こちらも学習できたようです。
注意する点としては、仮定した分布を使って予測する計算グラフy_preとラベルデータy_が一致するようinferenceで設定する点と、精度確認のための近似させた分布を使って予測する計算グラフyを用意しておくところなどでしょうか。
また、各ニューロンが確率分布になるので、同じデータをx_に与えたとしても、予測結果yは当然確率によって値が変動します。
そのため、精度を確認する際には、ある程度同じデータを与えてサンプリングを行い、どちらのラベルである確率が高いかを見て判断させています。
y_samples = y.sample(samples_num).eval(feed_dict={x_: train_x})
acc = (np.round(y_samples.sum(axis=0) / samples_num) == train_y2).mean()
y_samples = y.sample(samples_num).eval(feed_dict={x_: test_x})
test_acc = (np.round(y_samples.sum(axis=0) / samples_num) == test_y2).mean()がその該当箇所になります。
ニューラルネットワークと同様にエポックを回してみましたが、序盤から精度が高く、むしろエポックを重ねて精度が上がるかというとそうでもないし、ベイズ的に考えたら確かにあまり意味がないようにも思います。
また、今回は隠れ層なしでしたけども、隠れ層を入れた場合には同じような作り方で良いのかも気になるところです。
まとめ
今回は、ベイズニューラルネットワークの基本的な考え方とEdwardを用いた実装例をご紹介しました。
今回はあまり触れませんでしたが、ベイズであるためモデルの予測も不確実性と共に表現することができ、より実務の適用において、やれることの幅が広がるものになると思います。
Edwardは今後TensorFlowに取り込まれるとのことで、より一層ベイズニューラルネットワークやベイズ深層学習の代表的なライブラリになりえるかもしれません。
今後の発展にも注目ですが、この記事を通じてベイズ推論とベイズニューラルネットワークの基本を理解し、Edwardライブラリの使い方を学んでいただければ幸いです。