※本コラムは、以前に個人ブログとして公開していた内容を、加筆・再構成のうえ掲載しております。技術的な内容は執筆当時のものであり、現在とは異なる場合がございます。
こんにちは。Anagraftの伊藤です。
深層学習は特にコンピュータビジョン(CV)分野で優れたパフォーマンスを実現する可能性があります。 しかしそれらは直感的でなく、理解可能なコンポーネントへの分解も難しいため、解釈可能性が低くなりがちです。 そのため近年では、深層学習モデルが、画像のどこにフォーカスして予測したのかといった、判断根拠を可視化する方法が研究されています。
今回はそのような画像系深層学習の判断根拠可視化手法について、広く使われている手法Grad-CAMと、その改良版Grad-CAM++、さらにScore-CAMを、TensorFlow/Kerasで実装し、比較してみます。 なお、元記事のコードはTensorFlow 1系で書かれていたため、本コラムのコード例は現行のTensorFlow 2系で動作するよう書き直しています(ロジックは元の実装と同一です)。実験結果や可視化の図は元記事執筆時のものです。

目次
深層学習の判断根拠解釈について
前述の通り、深層学習はCV分野において優れたパフォーマンスを発揮しますが、モデルの解釈を得づらいといった点があります。 したがって、モデルの判断根拠を可視化し解釈することは重要な領域の1つです。
以下は、Grad-CAMによるモデル判断根拠可視化の例です。

判断根拠の可視化のメリットは主に以下の2つです。
- モデルの透明性を高めることができる
- 学習データのバイアスに気づくことができる
1つ目はこれまで記している通り、深層学習はモデルの解釈を得づらいという特徴がありますが、判断根拠の可視化により、解釈可能性の低さを改善し、モデルの透明性を向上させることができます。 これにより、モデルの予測ロジックを言語化でき、妥当性を評価できるため、実社会の責任の伴う場面にも適用しやすくなる可能性があります。
2つ目は、学習データのバイアスに気づくことができることです。 上記でご紹介した可視化例はGrad-CAMの論文から抜粋したもので、DoctorとNurseを分類するモデルの可視化例です。 左列は答えで、上の女性がNurse、下の女性がDoctorのラベルが付与されています。 中央列は、どうやら学習データに「Doctorには男性が多い/Nurseには女性が多い」というバイアスがかかっていたようで、モデルは人の顔や髪を見てどちらもNurseと予測してしまっているという様子を可視化で得ています。 右列では、性別のバイアスを学習データから取り除いて学習させた結果、人が持っている医療器具を注視するようになったということを表しています。 このように、判断根拠を可視化してみると、どうやら何か意図しない情報を使って予測しているかも?といったことに気づくことができます。
使用するデータセットと深層学習モデル
これから実装例を見ていくために、適当な深層学習モデルを用意してみます。
画像分類用のデータセットとして、以下のデータセットを利用します。
- Intel Image Classification: https://www.kaggle.com/datasets/puneet6060/intel-image-classification
上記データセットは、以下の6クラスにラベル付けされている画像データセットです。
- 建物(buildings)
- 森(forest)
- 雪山(glacier)
- 山(mountain)
- 海(sea)
- ストリート(street)
各クラスについて、枚数、比率、サンプル画像を何枚か確認してみると以下のような感じです。 いずれのクラスも同じくらいの比率で含まれており、各クラスごとに約2000個、合計12000個ほどの画像データが格納されているようです。
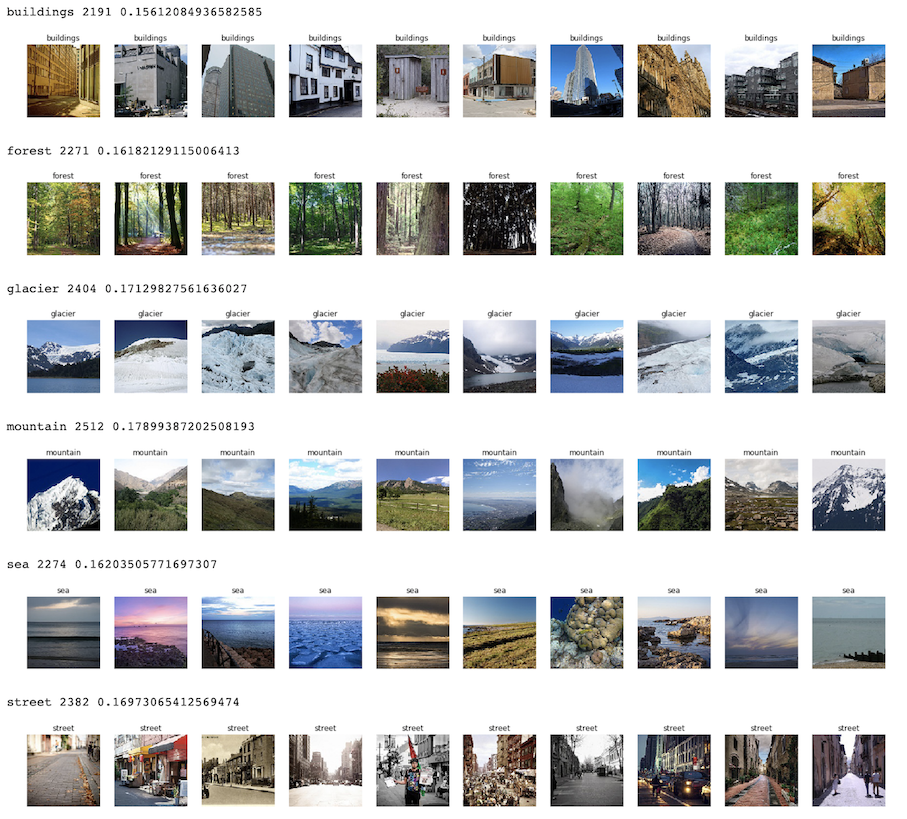
この時点で、どうやらglacierとmountainを正しく分類するのはやや難しそうな印象を受けます。
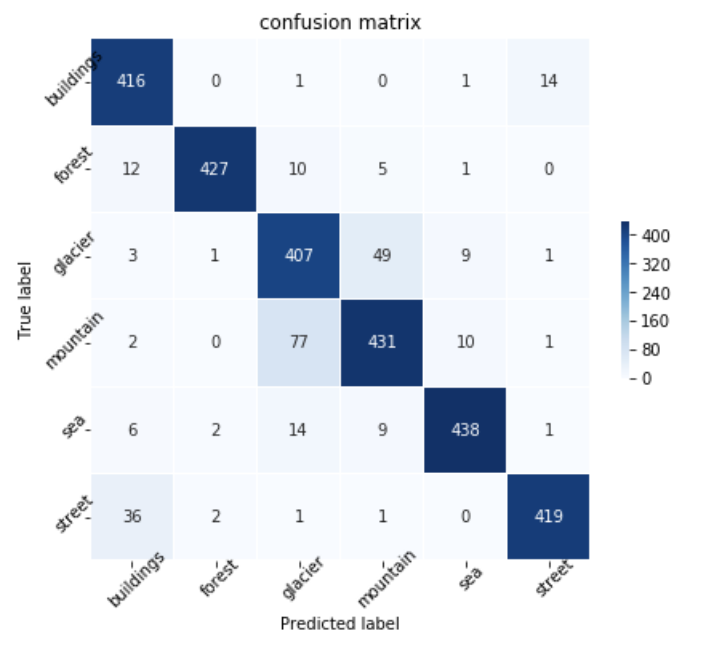
深層学習モデルは、学習済みのResNet50のファインチューニングでモデルを作ってみます。 train/testデータセットの作成などは省略しますが、以下のようにモデルを作成し、学習させてみたところ、90%ほどの精度となりました。 混同行列をプロットして確認してみると、やはりglacierとmountainは互いにやや間違えやすい傾向にありそうです。
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Input, Dense, GlobalAveragePooling2D, BatchNormalization
from tensorflow.keras.models import Model
def build_model(w, h, n_classes):
"""Build model function.
Args:
w (int): Width size of image.
h (int): Height size of image.
n_classes (int): The number of class.
Returns:
Model: Model.
"""
# Resnet
input_tensor = Input(shape=(w, h, 3)) # To change input shape
resnet50 = ResNet50(
include_top=False, # To change output shape
weights="imagenet", # Use pre-trained model
input_tensor=input_tensor, # Change input shape for this task
)
# fc layer
x = GlobalAveragePooling2D()(resnet50.output) # Add GAP for cam
output = Dense(n_classes, activation="softmax")(x) # Change output shape for this task
# model
model = Model(inputs=resnet50.input, outputs=output)
# frozen weights
for layer in model.layers[:-10]:
layer.trainable = False or isinstance(layer, BatchNormalization) # If Batch Normalization layer, it should be trainable
# compile
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"],
)
return model
# Build the model
model = build_model(w=W, h=H, n_classes=N_CLASSES)
# Finetuning the model
history = model.fit(
datagen_train.flow(
x_train,
y_train,
batch_size=BATCH_SIZE,
),
epochs=N_EPOCHS,
validation_data=datagen_test.flow(
x_test,
y_test,
batch_size=BATCH_SIZE,
),
)
Epoch 1/5
351/351 [==============================] - 70s 201ms/step - loss: 0.5062 - accuracy: 0.8201 - val_loss: 0.2515 - val_accuracy: 0.8917
Epoch 2/5
351/351 [==============================] - 48s 137ms/step - loss: 0.3234 - accuracy: 0.8817 - val_loss: 0.0313 - val_accuracy: 0.9024
Epoch 3/5
351/351 [==============================] - 49s 139ms/step - loss: 0.2801 - accuracy: 0.9011 - val_loss: 0.2366 - val_accuracy: 0.9020
Epoch 4/5
351/351 [==============================] - 48s 138ms/step - loss: 0.2494 - accuracy: 0.9080 - val_loss: 0.3192 - val_accuracy: 0.9102
Epoch 5/5
351/351 [==============================] - 49s 139ms/step - loss: 0.2238 - accuracy: 0.9169 - val_loss: 0.1859 - val_accuracy: 0.9081
Grad-CAMの実装について
それでは、それぞれの判断根拠の可視化手法を実装し、試してみます。
まずはGrad-CAMです。 論文は以下になります。
- Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization: https://arxiv.org/abs/1610.02391
Grad-CAMは2016年に発表されましたが、それより少し以前に発表されたCAM(Class Activation Mapping)の拡張として発表されました。 ロジックの数式は以下です。 (他のCAM手法との比較がわかりやすくなるように、こちらで表現を少し変えています)
\( L^c_{Grad\text{-}CAM} = ReLU\Bigl(\displaystyle\sum_k \alpha^c_k A^k\Bigr), \hspace{1em} \alpha^c_k = \displaystyle\frac{1}{Z}\sum_{i}\sum_{j}\frac{\partial y^c}{\partial A^k_{ij}} \)
ここで、\( A^k \)は最後の畳み込み層が出力する\( k \)番目の特徴マップ、\( y^c \)はクラス\( c \)のスコア、\( Z \)は特徴マップの画素数です。 すなわち、クラススコアの特徴マップに対する勾配を空間方向に平均したものを重み\( \alpha^c_k \)として、特徴マップの重み付き和をとった形になっています。
元となったCAMは、一般的な畳み込み層にGlobal Average Poolingをかけて学習させた時の特徴マップの出力は、その先の全結合層の重み\( w^c_k \)がクラス分類の重要度を特徴マップ上で表すと考えられる、という考えから提案されています。
\( L^c_{CAM} = \displaystyle\sum_k w^c_k A^k \)
つまり、このままだとモデルとしてGlobal Average Poolingが必要になるのですが、それを勾配で代用できることを示し、どんなモデルアーキテクチャにもCAMのような可視化が可能だとしたのがGrad-CAMになります。 実は先ほどの深層学習モデルを準備している段階でGlobal Average Pooling層を追加しましたが、Grad-CAM自体はGAP層を前提としないため、これはなくても適用できます。
ランプ関数(ReLU)はクラスに対するマイナスの勾配を無視するためです。 意図は微妙にクリアではないですが、個人的には、勾配がマイナスに寄与している=そのクラスではない、を表すとし、そのクラスと判断した根拠の可視化からは除外して考えているだけなのかなと理解しています。
Grad-CAMの実装は以下のようになります。
(元記事ではTensorFlow 1系のK.gradientsを使っていましたが、TensorFlow 2系ではtf.GradientTapeで勾配を取得します)
def grad_cam(model, x, layer_name):
"""Grad-CAM function.
Args:
model (Model): Model.
x (np.ndarray): Input.
layer_name (str): Get layer name.
Returns:
tuple[int, np.ndarray]: Predicted class, heatmap of CAM.
"""
cls = int(np.argmax(model.predict(x)))
grad_model = Model(
inputs=model.input,
outputs=[model.get_layer(layer_name).output, model.output],
)
# Get outputs and grads
with tf.GradientTape() as tape:
conv_output, predictions = grad_model(x)
y_c = predictions[:, cls]
grads = tape.gradient(y_c, conv_output)
output, grads_val = conv_output[0].numpy(), grads[0].numpy()
weights = np.mean(grads_val, axis=(0, 1)) # Passing through GlobalAveragePooling
cam = np.dot(output, weights) # multiply
cam = np.maximum(cam, 0) # Passing through ReLU
if np.max(cam) > 0:
cam /= np.max(cam) # scale 0 to 1.0
return cls, cam
なお、xはバッチサイズ1の入力を、layer_nameには最後の畳み込み層の名前(今回のResNet50ではconv5_block3_out)を指定する想定です。
また、本コラムではsoftmax出力に対する勾配を取っていますが、Keras公式のGrad-CAM実装例のように、最終層のsoftmaxを外してlogit(softmax適用前のスコア)に対する勾配を取る実装も一般的です。
Grad-CAM++の実装について
Grad-CAM++は、2017年に、Grad-CAMの改良版として発表されました。
- Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks: https://arxiv.org/abs/1710.11063
こちらは、特徴マップにかかる重みのようなものがあったとしたら、それはどう表現されるかを、これまでの論文で出てきた数式からガリガリと紐解いており、以下のように表現しています。
\( w^c_k = \displaystyle\sum_{i}\sum_{j}\alpha^{kc}_{ij}\cdot ReLU\Bigl(\frac{\partial y^c}{\partial A^k_{ij}}\Bigr), \hspace{1em} \alpha^{kc}_{ij} = \displaystyle\frac{\displaystyle\frac{\partial^2 y^c}{(\partial A^k_{ij})^2}}{2\displaystyle\frac{\partial^2 y^c}{(\partial A^k_{ij})^2}+\displaystyle\sum_a\sum_b A^k_{ab}\displaystyle\frac{\partial^3 y^c}{(\partial A^k_{ij})^3}} \)
勾配を空間方向に一様に平均するのではなく、画素ごとの重要度\( \alpha^{kc}_{ij} \)で重み付けする形になっています。 これにより、特徴マップの中でクラス予測に影響を与えるがその領域の大きさが大きくなかったものは、これまで捉えられていませんでしたが、捉えられるようになりました。 こちらを実装すると、以下のようになります。
def grad_cam_plus_plus(model, x, layer_name):
"""Grad-CAM++ function.
Args:
model (Model): Model.
x (np.ndarray): Input.
layer_name (str): Get layer name.
Returns:
tuple[int, np.ndarray]: Predicted class, heatmap of CAM.
"""
cls = int(np.argmax(model.predict(x)))
grad_model = Model(
inputs=model.input,
outputs=[model.get_layer(layer_name).output, model.output],
)
# Get outputs and grads
with tf.GradientTape() as tape:
conv_output, predictions = grad_model(x)
y_c = predictions[:, cls]
grads = tape.gradient(y_c, conv_output)
conv_output = conv_output[0].numpy()
grads_val = grads[0].numpy()
score = float(y_c.numpy()[0])
# first / second / third derivative
conv_first_grad = np.exp(score) * grads_val
conv_second_grad = np.exp(score) * grads_val ** 2
conv_third_grad = np.exp(score) * grads_val ** 3
# Calculate weight alpha
global_sum = np.sum(conv_output.reshape((-1, conv_first_grad.shape[2])), axis=0)
alpha_num = conv_second_grad
alpha_denom = conv_second_grad * 2.0 + conv_third_grad * global_sum.reshape((1, 1, conv_first_grad.shape[2]))
alpha_denom = np.where(alpha_denom != 0.0, alpha_denom, np.ones(alpha_denom.shape))
alphas = alpha_num / alpha_denom
weights = np.maximum(conv_first_grad, 0.0)
alpha_normalization_constant = np.sum(np.sum(alphas, axis=0), axis=0)
alphas /= alpha_normalization_constant.reshape((1, 1, conv_first_grad.shape[2]))
deep_linearization_weights = np.sum((weights * alphas).reshape((-1, conv_first_grad.shape[2])), axis=0)
cam = np.sum(deep_linearization_weights * conv_output, axis=2) # multiply
cam = np.maximum(cam, 0) # Passing through ReLU
if np.max(cam) > 0:
cam /= np.max(cam) # scale 0 to 1.0
return cls, cam
Score-CAMの実装について
Score-CAMは、2019年10月に発表された手法です。
- Score-CAM: Score-Weighted Visual Explanations for Convolutional Neural Networks: https://arxiv.org/abs/1910.01279
勾配での表現は、時々入力層のわずかな小さな変化に対しても、過剰に大きな値を返してしまう問題があります。 これはGrad-CAMやGrad-CAM++においても指摘されていたことでした。
そこで、この論文では、特徴量ヒートマップを勾配を使わないで作成する方法を提案しています。
\( L^c_{Score\text{-}CAM} = ReLU\Bigl(\displaystyle\sum_k \alpha^c_k A^k\Bigr), \hspace{1em} \alpha^c_k = f\bigl(X \circ H^k\bigr)_c \)
\( X \)はインプット画像、\( H^k \)は特徴マップ\( A^k \)を入力サイズに拡大し正規化したマスク、\( f(\cdot)_c \)はマスクをかけた画像をモデルに入力した時のクラス\( c \)のスコアです。 すなわち、「特徴マップ×画像」のスコアを重みとして表現するような形をしています。 これを実装すると、以下のようになります。
def score_cam(
model,
x,
layer_name,
max_N=-1,
):
"""Score-CAM function.
Args:
model (Model): Model.
x (np.ndarray): Input.
layer_name (str): Get layer name.
max_N (int): max N.
Returns:
tuple[int, np.ndarray]: Predicted class, heatmap of CAM.
"""
cls = int(np.argmax(model.predict(x)))
act_map_array = Model(inputs=model.input, outputs=model.get_layer(layer_name).output).predict(x)
# extract effective maps
if max_N != -1:
act_map_std_list = [np.std(act_map_array[0, :, :, k]) for k in range(act_map_array.shape[3])]
unsorted_max_indices = np.argpartition(-np.array(act_map_std_list), max_N)[:max_N]
max_N_indices = unsorted_max_indices[np.argsort(-np.array(act_map_std_list)[unsorted_max_indices])]
act_map_array = act_map_array[:, :, :, max_N_indices]
input_shape = model.input_shape[1:] # get input shape (height, width, channels)
# 1. upsampled to original input size (cv2.resize dsize is (width, height))
act_map_resized_list = [cv2.resize(act_map_array[0,:,:,k], (input_shape[1], input_shape[0]), interpolation=cv2.INTER_LINEAR) for k in range(act_map_array.shape[3])]
# 2. normalize the raw activation value in each activation map into [0, 1]
act_map_normalized_list = []
for act_map_resized in act_map_resized_list:
if np.max(act_map_resized) - np.min(act_map_resized) != 0:
act_map_normalized = (act_map_resized - np.min(act_map_resized)) / (np.max(act_map_resized) - np.min(act_map_resized))
else:
act_map_normalized = act_map_resized
act_map_normalized_list.append(act_map_normalized)
# 3. project highlighted area in the activation map to original input space by multiplying the normalized activation map
masked_input_list = []
for act_map_normalized in act_map_normalized_list:
masked_input = np.copy(x)
for k in range(3):
masked_input[0, :, :, k] *= act_map_normalized
masked_input_list.append(masked_input)
masked_input_array = np.concatenate(masked_input_list, axis=0)
# 4. feed masked inputs into CNN model (the output is already softmax probability)
pred_from_masked_input_array = model.predict(masked_input_array)
# 5. define weight as the score of target class
weights = pred_from_masked_input_array[:, cls]
# 6. get final class discriminative localization map as linear weighted combination of all activation maps
cam = np.dot(act_map_array[0, :, :, :], weights) # multiply
cam = np.maximum(0, cam) # Passing through ReLU
if np.max(cam) > 0:
cam /= np.max(cam) # scale 0 to 1.0
return cls, cam
各解釈手法の結果比較
各手法の実装ができましたので、各クラスの判断根拠の可視化を比較してみます。
建物(buildings)
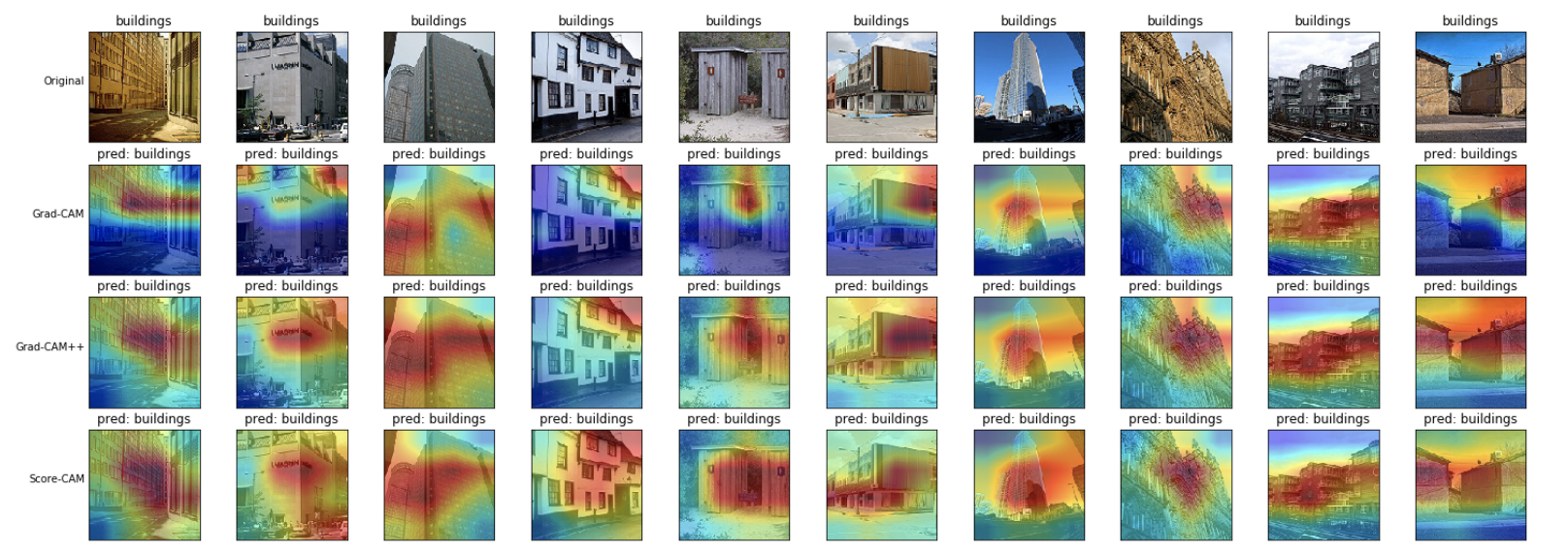
モデルは建物の全体部分に注目しているような可視化結果が得られました。 Grad-CAM++とScore-CAMの方が、Grad-CAMよりも、より建物の全体を見ているような結果となりました。 Grad-CAM++とScore-CAMはそれほど大きな違いはないように見えます。
森(forest)
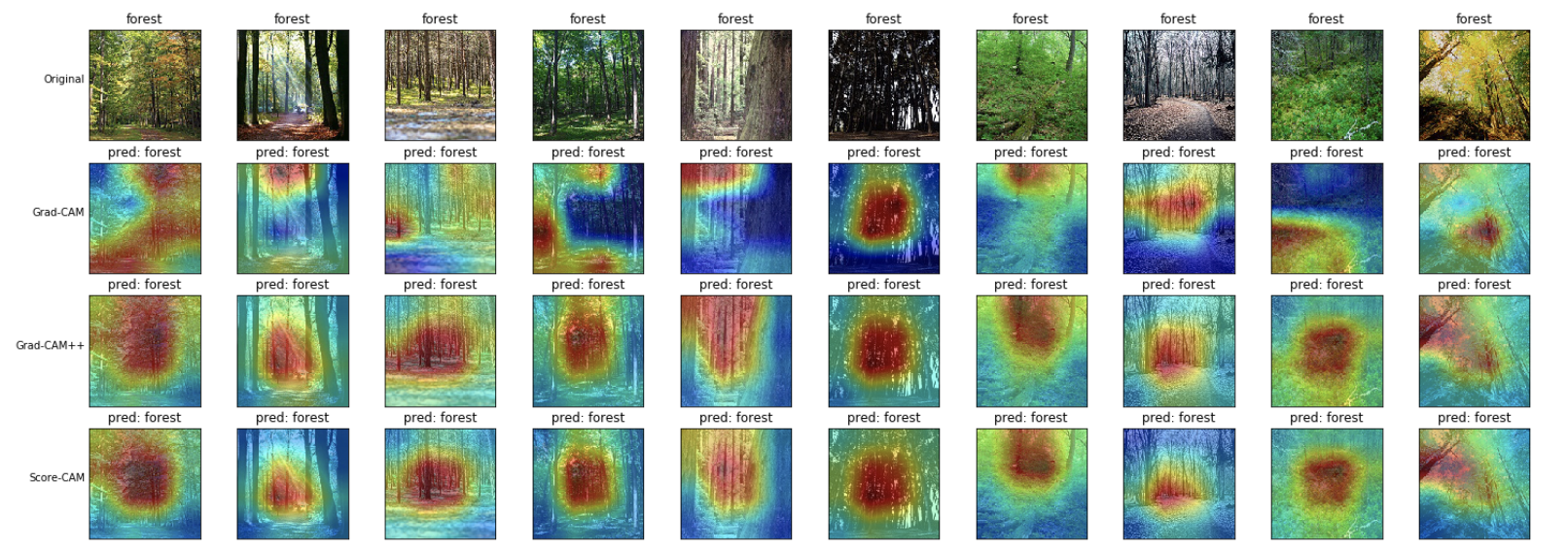
木の幹の部分を見つけて、森と予測しているように見えます。 特に、Grad-CAM++とScore-CAMの方が、Grad-CAMよりも顕著にその特徴を捉えているように見えます。
雪山(glacier)
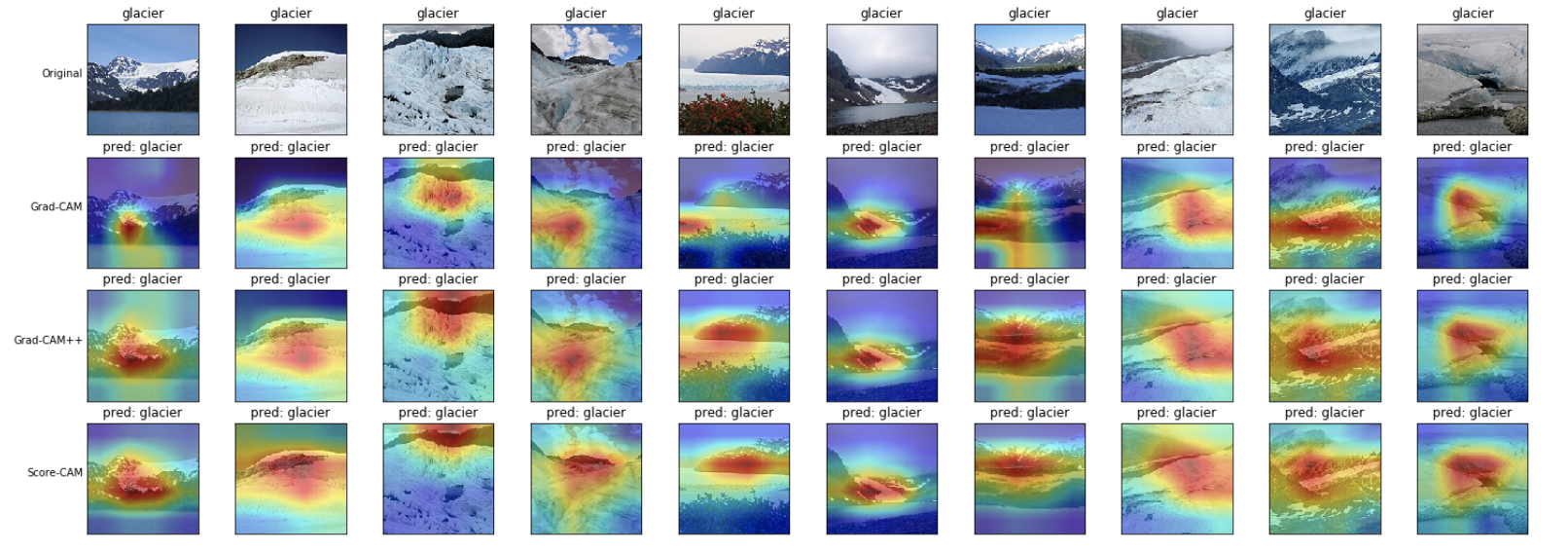
山の形を見ている?ような結果となりました。 山の色も見ているのかもしれません。 これに関しては、いずれの可視化手法も大きな違いはなさそうに見えます。
山(mountain)
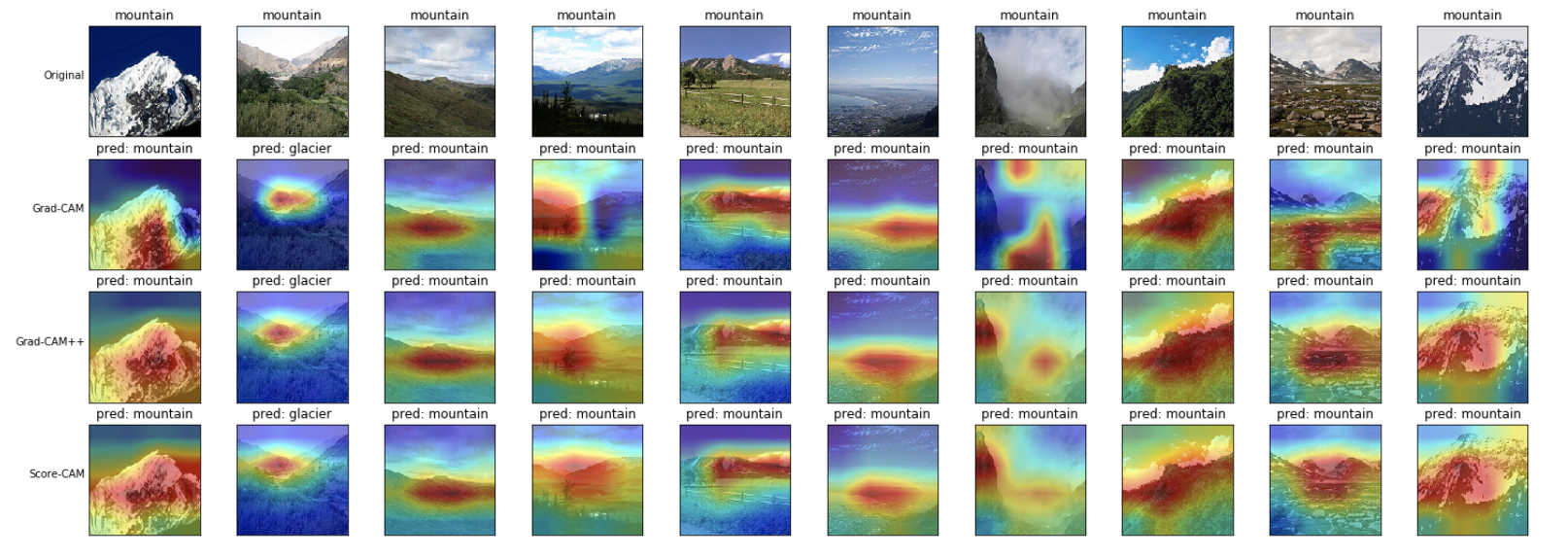
こちらも山の形を見ているような、雪山と同じような結果となりました。 山の画像にも、色的に見ると雪山の方が正しいような気もする画像が含まれており、判断に迷います。 そのくらい、差別化できるような画像要素を見つけられていないように思います。 またこちらも、いずれの可視化手法も大きな違いはなさそうです。
海(sea)

こちらは、海の表面や水平線を見ているような可視化結果となりました。 Grad-CAM++とScore-CAMの方が、Grad-CAMよりもより海全体を捉えているように見えます。
ストリート(street)
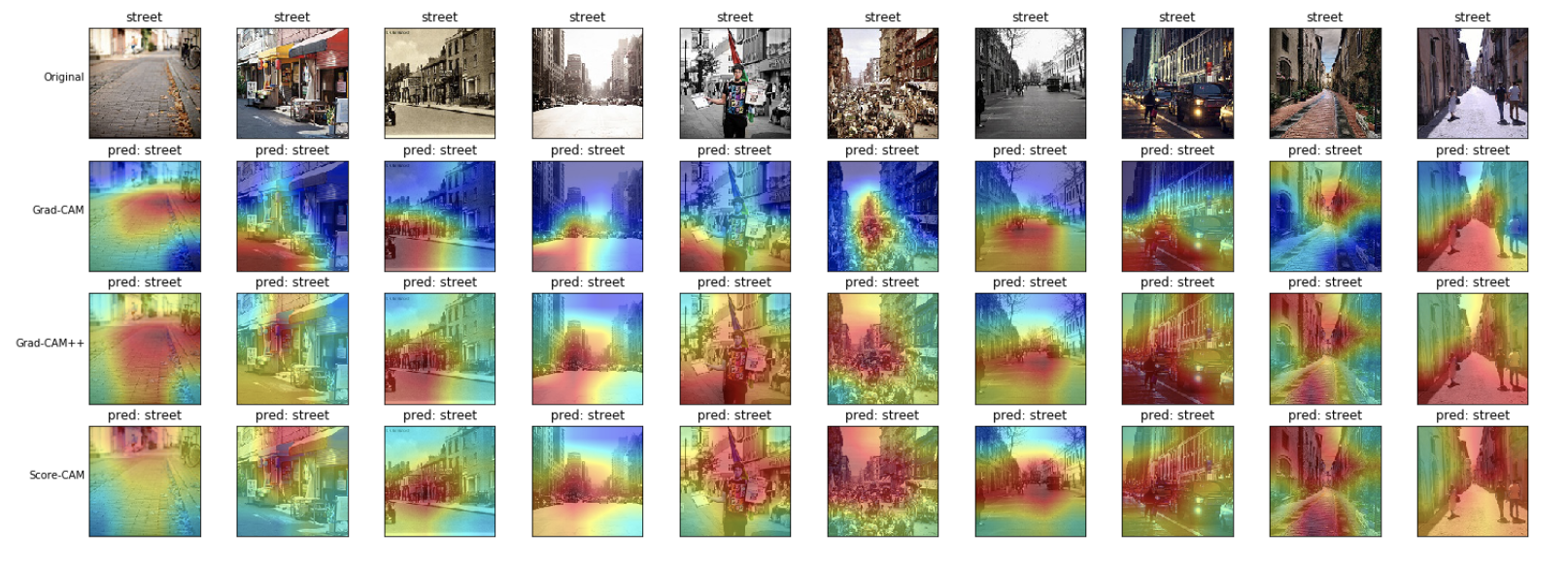
モデルは、路面およびその両側に建つ建物について見ているような結果となりました。 こちらも、Grad-CAM++とScore-CAMの方が、より全体を捉えているように見えます。
まとめ
今回は、KerasでGrad-CAM、Grad-CAM++、Score-CAMの実装および結果の比較をしてみました。
Grad-CAMは、クラス予測に関連のある部分のごく一部にしか反応できていなかったように見えますが、Grad-CAM++とScore-CAMの方が、より関連のある部分全体を可視化してくれていたように見えました。 Grad-CAM++とScore-CAMには、可視化にはそれほど大きな違いはないようです。
また、それぞれの手法の実行にかかる時間は、新しくなるにつれて時間がかかります。(Score-CAM > Grad-CAM++ > Grad-CAM) Grad-CAMよりもGrad-CAM++は微分計算などが加えられていて当然実行時間は長くなりますし、また、Score-CAMはマスク画像を複数枚推論する必要があるために実行時間がかかっているように思います。
実行時間を気にしないならば、個人的には、Grad-CAM++かScore-CAMがおすすめかと思いました。
このような手法で、上記の判断根拠可視化のメリットで示した通り、学習データのバイアスなどがないかを感覚的に調べたり、モデルの透明性や妥当性を示すのに使用すると良いでしょう。
可視化もある意味定性的な判断にはなってしまうのですが、やはり画像は人間もなんとなく認識している場合が多く、人間が見れば確かにこの画像はネコなんだけど、モデルはなんでそう思ったのか、をうまく言語化できなくてビジネス報告しづらい時に、これらのような表現が活用できます。
その後の発展・最新動向(2026年時点)
元記事の執筆以降も、判断根拠の可視化(CAM系手法)は活発に発展しています。主なポイントを整理します。
- CAM系手法のさらなる発展: 本コラムで紹介した3手法の後にも、XGrad-CAM、Ablation-CAM、Eigen-CAM、LayerCAM、FullGradなど多くの派生手法が提案されています。特にHiResCAMは、Grad-CAMのヒートマップが「モデルが実際に使った根拠」を必ずしも忠実に反映しないケースがあることを指摘し、忠実性(faithfulness)を保証する代替手法として提案されました。可視化の「見栄えの良さ」と「忠実さ」は別物である、という問題意識が広がったのは大きな変化です。
- ライブラリの充実: 現在では、これらの手法を自前で実装しなくても、ライブラリで手軽に利用できるようになりました。PyTorchではpytorch-grad-camが定番で、本コラムで扱った3手法を含む10種類以上のCAM系手法を、画像分類だけでなく物体検出・セグメンテーション・画像類似度などのタスクにも適用できます。TensorFlow/Kerasではtf-keras-visなどが利用できます。
- Vision Transformer(ViT)時代の解釈手法: 画像認識の主役がCNNからViTへ広がったことに伴い、Attention Rollout(アテンションの流れを層をまたいで追跡する手法)などViT向けの解釈手法も登場しました。CAM系手法も、トークン列を2次元の特徴マップに並べ替えることでViTに適用でき、pytorch-grad-camもViTをサポートしています。CNNとViTのどちらでも、判断根拠の可視化という考え方は引き続き有効です。
- 可視化の信頼性評価: 「もっともらしいヒートマップが、本当にモデルの判断根拠を表しているのか」を検証する研究も進みました。サニティチェック(モデルの重みをランダム化しても可視化結果が変わらないなら、その可視化はモデルを説明していない、という検証)や、重要領域を削除・挿入した時のスコア変化による定量評価(Deletion/Insertion、ROADなど)が標準的に行われるようになっています。可視化手法を業務で使う際も、こうした観点で吟味することをおすすめします。
- 説明可能性への社会的要請: EUのAI規則(AI Act)をはじめ、AIシステムの透明性・説明可能性を求める制度的な動きが世界的に進んでいます。判断根拠の可視化は、それ単体で説明責任を果たせるものではありませんが、モデル開発時のデバッグやバイアス検出、ステークホルダーへの説明材料として、実務上の重要性はますます高まっています。
参考文献
- Selvaraju, R. R., et al. (2017). Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. ICCV 2017.
- Chattopadhyay, A., et al. (2018). Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks. WACV 2018.
- Wang, H., et al. (2020). Score-CAM: Score-Weighted Visual Explanations for Convolutional Neural Networks. CVPR 2020 Workshops.
- Zhou, B., et al. (2016). Learning Deep Features for Discriminative Localization(CAM). CVPR 2016.
- Draelos, R. L., Carin, L. (2020). Use HiResCAM instead of Grad-CAM for faithful explanations of convolutional neural networks. arXiv.
- pytorch-grad-cam(GitHub): https://github.com/jacobgil/pytorch-grad-cam
- tf-keras-vis(GitHub): https://github.com/keisen/tf-keras-vis
- Keras公式 Grad-CAM実装例: https://keras.io/examples/vision/grad_cam/
- Adebayo, J., et al. (2018). Sanity Checks for Saliency Maps. NeurIPS 2018.
- Rong, Y., et al. (2022). A Consistent and Efficient Evaluation Strategy for Attribution Methods(ROAD). ICML 2022.
- Intel Image Classification(Kaggle): https://www.kaggle.com/datasets/puneet6060/intel-image-classification