※本コラムは、以前に個人ブログとして公開していた内容を、加筆・再構成のうえ掲載しております。技術的な内容は執筆当時のものであり、現在とは異なる場合がございます。
こんにちは。Anagraftの伊藤です。
機械学習の技術は、ビジネスや意思決定プロセスにおいてますます重要性を増しています。しかし、意思決定者にとって本当に重要なのは、モデルの精度がどれだけ高いか、最新手法(SOTA)かどうか、ではありません。実際の意味で役に立つか、つまり業務オペレーションとして実現可能か、利益やコストのインパクトとして意味があるか、という点です。
本記事では、クレジットカードの不正利用を予測するモデルの実装を題材に、損益行列(コスト・ベネフィット行列)を用いて「インパクトの目線」で機械学習モデルを評価する流れに焦点を当てます。
なお、元記事の執筆は2018年で、コード中のライブラリ(scikit-learn、imbalanced-learn、pandasなど)はその後APIが変更されている箇所があります。本コラムのコード例は現行のライブラリで動くよう修正しています。

データの確認と準備
Kaggleのデータセットに、クレジットカードの利用履歴を主成分化したいくつかのカラムと、それが不正利用であったかどうかのラベルが付いたデータがあります。今回はこのデータを使って、不正利用予測モデルを作り、評価するところまでを行います。
特徴量はほとんどが主成分化されているため、どのカラムが何を表すのかは不明です。欠損値もありません。クラスを集計してみると、以下のようにかなり不均衡なデータになっています。現実でも不正利用というのは稀ですので、よくある設定だと思います。
| データ件数 | 不正利用フラグ=1の件数 | 不正利用データの割合 |
|---|---|---|
| 284,807件 | 492件 | 0.00173 |
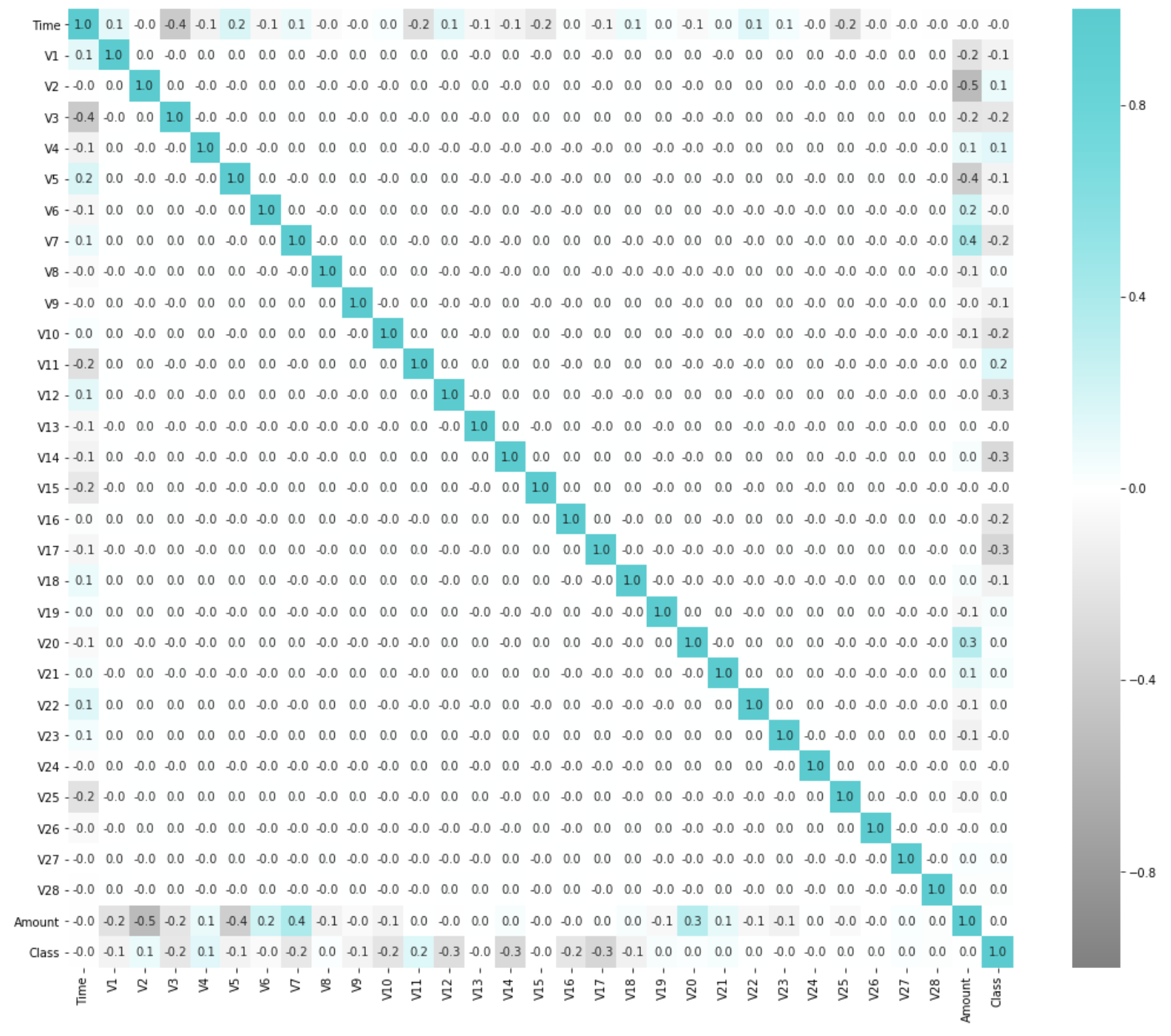
相関行列のヒートマップを可視化してみると以下のような感じです(不正利用クラスは最下行・最右列のClass)。特別どこかのカラムに強く相関しているわけではなさそうです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('./data/creditcard.csv')
plt.figure(figsize=(18, 15))
sns.heatmap(df.corr(), annot=True, vmax=1, vmin=-1, fmt='.1f', cmap='viridis')
plt.show()
次に教師データを作成します。上記の通りクラス別のサンプル数がかなり偏っているので、モデルをきちんと学習させられるよう、データをサンプリングして偏りを揃えます。アンダーサンプリングやオーバーサンプリングが揃っているライブラリimbalanced-learn(imblearn)を使います。
元記事ではrus.fit_sample(...)を使っていましたが、imbalanced-learnの現行バージョンではfit_resample(...)に名称が変更されています。本コラムのコードは現行APIに合わせています。
from imblearn.under_sampling import RandomUnderSampler
cols = df.columns.tolist()
cols.remove('Class')
positive_cnt = int(df['Class'].sum())
rus = RandomUnderSampler(sampling_strategy={0: positive_cnt, 1: positive_cnt}, random_state=0)
data_x_sample, data_y_sample = rus.fit_resample(df[cols], df['Class'])
len(data_x_sample), len(data_y_sample), df['Class'].sum() # (984, 984, 492)
不正取引(Class = 1)が圧倒的に少ないので、これに合わせて不正取引でないデータをアンダーサンプリングしました。
続いて、使う特徴量をいくつかにピックアップします。分類モデルの学習に効く特徴量を探すため、scikit-learnのRFECVを使います。再帰的特徴除去(Recursive Feature Elimination: RFE)は、まず全特徴量でモデルを学習し、最も重要度の低い特徴量を除去して性能を再計算する、という処理を繰り返す手法です。重要度の指標にはfeature_importances_やcoef_が使われます。これを交差検証の中で行うのがRFECVです。
from sklearn import ensemble, tree, feature_selection
from xgboost import XGBClassifier
from tqdm import tqdm
# 特徴量を選択する
feature_importance_models = [
ensemble.AdaBoostClassifier(),
ensemble.ExtraTreesClassifier(),
ensemble.GradientBoostingClassifier(),
ensemble.RandomForestClassifier(),
tree.DecisionTreeClassifier(),
XGBClassifier(),
]
df_rfe_cols_cnt = pd.DataFrame(index=cols)
df_rfe_cols_cnt['cnt'] = 0
for model in tqdm(feature_importance_models):
rfe = feature_selection.RFECV(model, step=3)
rfe.fit(data_x_sample, data_y_sample)
rfe_cols = df[cols].columns.values[rfe.get_support()]
df_rfe_cols_cnt.loc[rfe_cols, 'cnt'] += 1
df_rfe_cols_cnt.plot(kind='bar', figsize=(15, 5))
plt.show()
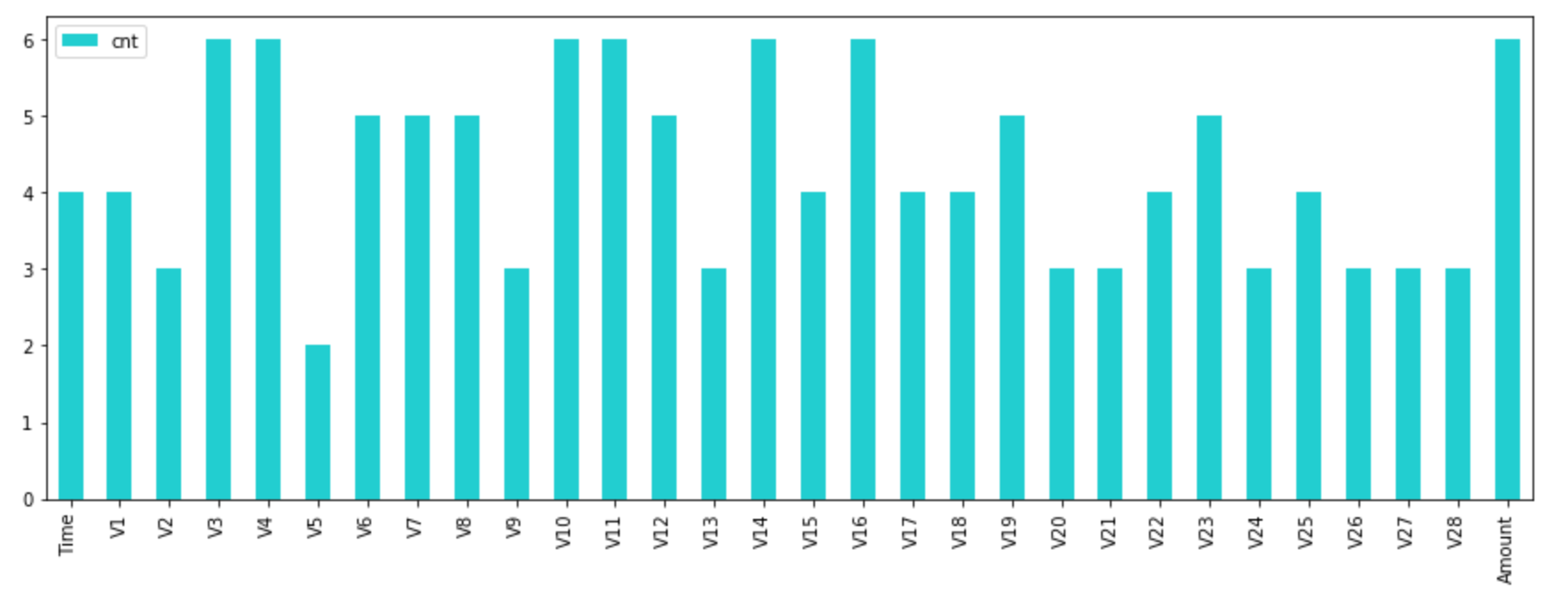
このように、どの変数がどのくらい選ばれたかが分かります。上記6つのモデル中4つ以上から選択された、以下の特徴量を使うことにしました。
x_cols = df_rfe_cols_cnt[df_rfe_cols_cnt['cnt'] >= 4].index
x_cols
# Index(['Time', 'V1', 'V3', 'V4', 'V6', 'V7', 'V8', 'V10', 'V11', 'V12', 'V14',
# 'V15', 'V16', 'V17', 'V18', 'V19', 'V22', 'V23', 'V25', 'Amount'],
# dtype='object')
なお、今回のデータは規模も小さく、全特徴量を使っても問題なく学習できるため、以降のモデル学習では特徴量を絞らず全カラムを使っています。上のRFECVの結果は、どの特徴量が効いているかを把握するための参考として確認した形です。
モデル学習
それではモデルを作ってみます。今回はデータ自体が主成分化されて扱いやすい状態ですので、いくつかの代表的なモデルを組み合わせた投票(Voting)モデルを作ってみます。
まずは複数のモデルを学習させます。後で精度を見ながら選ぶので、ひとまず思いついたものを並べてみました。
元記事では結果をpandas.DataFrame.appendで蓄積していましたが、このメソッドはpandas 2.0で削除されました。以下のコードは、結果をリストに貯めて最後にpd.DataFrameを作る形に修正しています。
from sklearn import (ensemble, gaussian_process, linear_model, naive_bayes,
neighbors, tree, discriminant_analysis, model_selection)
models = [
ensemble.AdaBoostClassifier(),
ensemble.BaggingClassifier(),
ensemble.ExtraTreesClassifier(),
ensemble.GradientBoostingClassifier(),
ensemble.RandomForestClassifier(),
gaussian_process.GaussianProcessClassifier(),
linear_model.LogisticRegressionCV(),
linear_model.RidgeClassifierCV(),
naive_bayes.BernoulliNB(),
naive_bayes.GaussianNB(),
neighbors.KNeighborsClassifier(),
tree.DecisionTreeClassifier(),
tree.ExtraTreeClassifier(),
discriminant_analysis.LinearDiscriminantAnalysis(),
discriminant_analysis.QuadraticDiscriminantAnalysis(),
XGBClassifier(),
]
records = []
for model in tqdm(models):
name = model.__class__.__name__
cv_rlts = model_selection.cross_validate(
model, data_x_sample, data_y_sample, scoring='accuracy', cv=10, return_train_score=True)
for i in range(10):
records.append({'name': name,
'train_accuracy': cv_rlts['train_score'][i],
'valid_accuracy': cv_rlts['test_score'][i],
'time': cv_rlts['fit_time'][i]})
df_compare = pd.DataFrame(records)
plt.figure(figsize=(12, 8))
sns.boxplot(data=df_compare, y='name', x='valid_accuracy', orient='h', linewidth=0.5, width=0.5)
plt.grid()
plt.show()
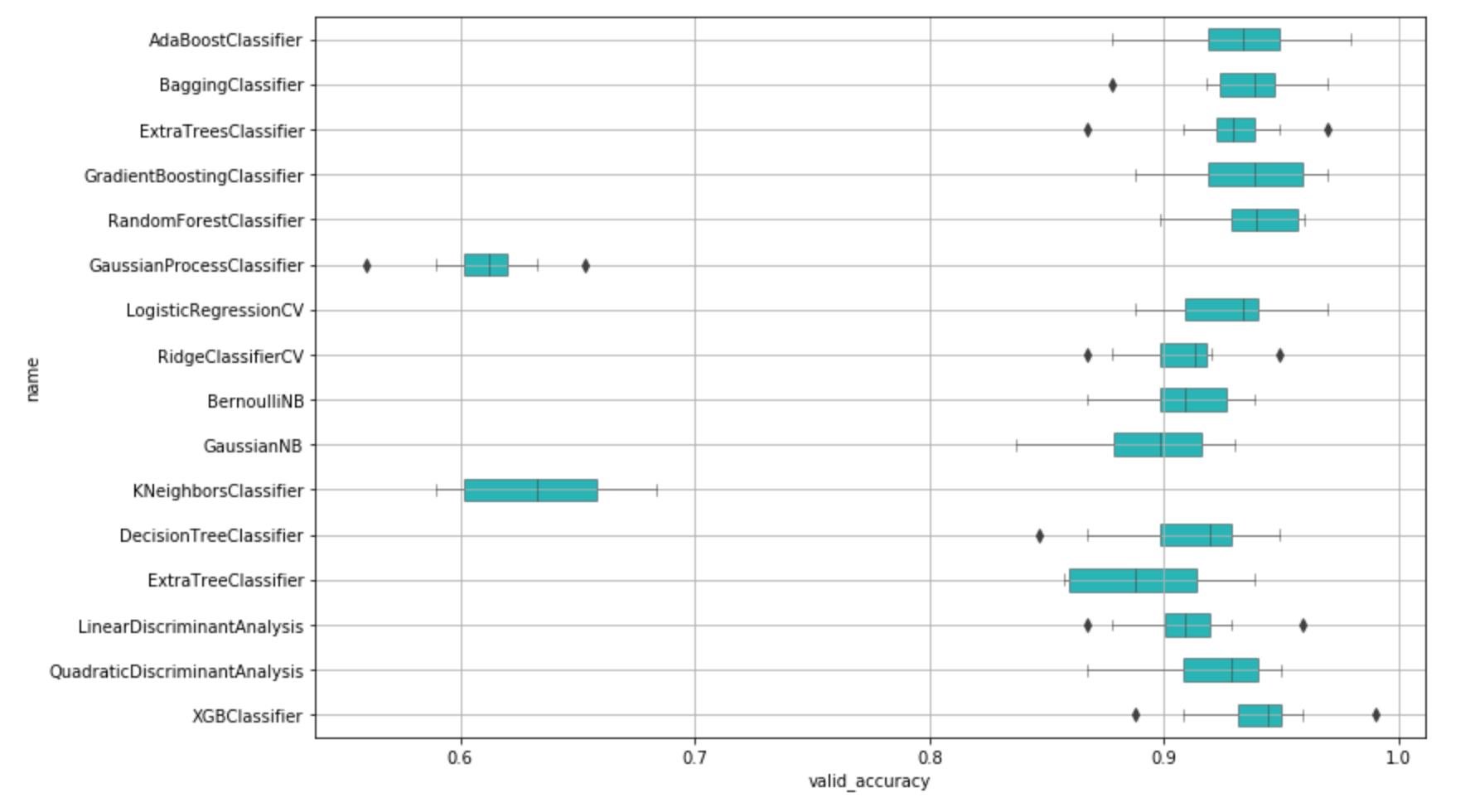
XGBoostに続いて、AdaBoost、バギング、勾配ブースティングあたりが良さそうです。valid_accuracyで平均すると、最高で94.0%、続いて93.6%、93.4%…という精度が出ました(精度の数値は一例で、乱数により多少前後します)。
それでは、この中から精度の良いモデルを複数選んで、まずはハイパーパラメータをデフォルトのまま投票モデルを学習させてみます。
vote_models = [
('abc', ensemble.AdaBoostClassifier()),
('bc', ensemble.BaggingClassifier()),
('etsc', ensemble.ExtraTreesClassifier()),
('gbc', ensemble.GradientBoostingClassifier()),
('rfc', ensemble.RandomForestClassifier()),
('lrcv', linear_model.LogisticRegressionCV()),
('xgbc', XGBClassifier()),
]
# Soft Voteモデル(predict_probaが使える)
vote_soft_model = ensemble.VotingClassifier(estimators=vote_models, voting='soft')
cv_rlts = model_selection.cross_validate(
vote_soft_model, data_x_sample, data_y_sample, cv=10, scoring='accuracy')
print('soft voting accuracy:', cv_rlts['test_score'].mean())
投票モデルを使うことで、精度が94.2%に上がりました。
後でスコアリング(予測確率の活用)をしたいので、ここではpredict_probaが使えるsoftを使います。hardは各モデルの予測を多数決でクラス判定するもので、softは各モデルのpredict_probaによる予測確率の平均をとって最終的にクラスを判定するものです。
このあと、各モデルでグリッドサーチを行って最適なハイパーパラメータを選び、再度投票モデルを学習させることもできますが、今回のデータではあまり大きな精度向上は見られませんでした。この辺りは、最後にわずかに数パーセント上がってくれないかな、くらいの位置づけだったりします。
精度によるモデル評価
改めて精度を確認します。混同行列とROC曲線を可視化してみました。
元記事ではsklearn.cross_validationモジュールを使っていましたが、これはscikit-learn 0.20で削除されています。現在はtrain_test_splitをsklearn.model_selectionから読み込みます。
from sklearn import metrics
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(
data_x_sample, data_y_sample, test_size=0.3, random_state=0)
vote_soft_model.fit(train_x, train_y)
pred = vote_soft_model.predict(valid_x)
pred_prob = vote_soft_model.predict_proba(valid_x)[:, 1] # ROC曲線には確率を使う
fig, axs = plt.subplots(ncols=2, figsize=(15, 5))
sns.heatmap(metrics.confusion_matrix(valid_y, pred), vmin=0, annot=True, fmt='d', cmap='viridis', ax=axs[0])
axs[0].set_xlabel('Predict')
axs[0].set_ylabel('Ground Truth')
axs[0].set_title('Accuracy: {}'.format(metrics.accuracy_score(valid_y, pred)))
fpr, tpr, thresholds = metrics.roc_curve(valid_y, pred_prob)
axs[1].plot(fpr, tpr)
axs[1].set_title('ROC curve')
axs[1].set_xlabel('False Positive Rate')
axs[1].set_ylabel('True Positive Rate')
axs[1].grid(True)
plt.show()
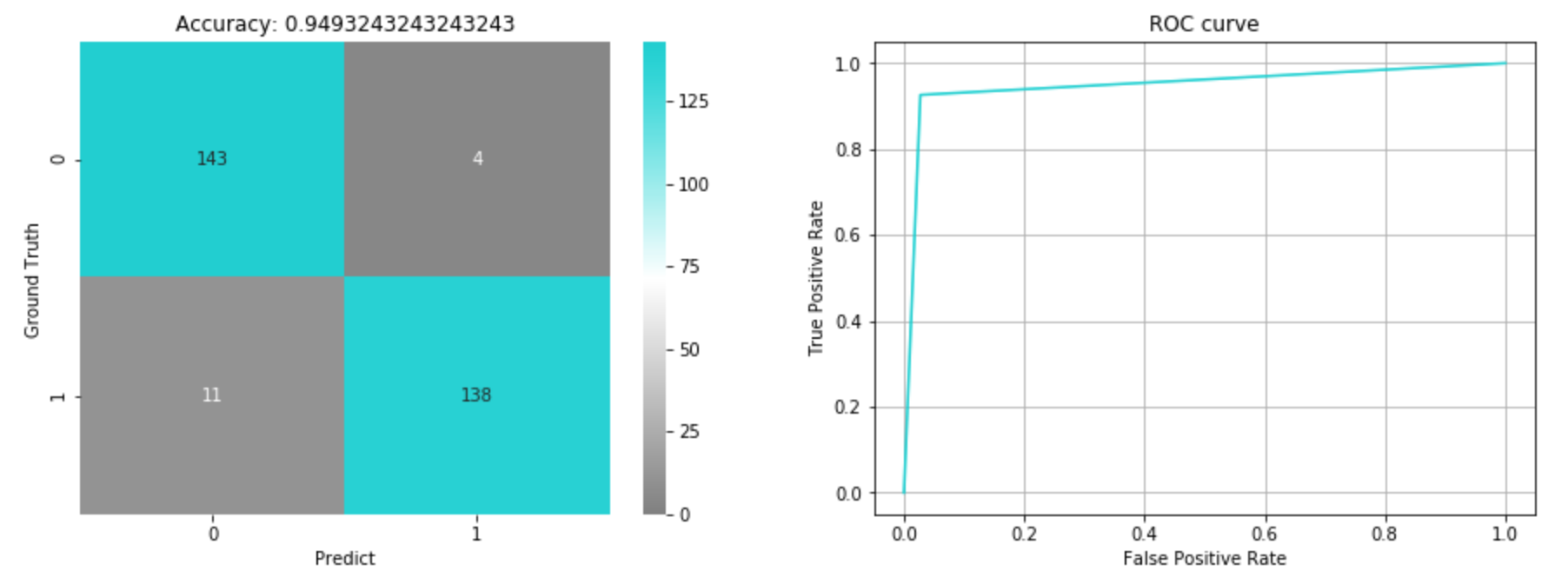
検証データに対する精度は0.949となりました。ただし、この検証データは、サンプリングで均衡を取った後のものです。実際にはGround Truthが0のデータの方が圧倒的に多い不均衡データですので、サンプリングで調整していた分を元の比率に戻して混同行列を出してみます。
# 実際の不均衡の比率に合わせた混同行列
confusion_matrix = metrics.confusion_matrix(valid_y, pred)
confusion_matrix_scaled = np.array([
confusion_matrix[0, :]*(len(df[df['Class'] == 0])/sum(confusion_matrix[0, :])),
confusion_matrix[1, :]*(len(df[df['Class'] == 1])/sum(confusion_matrix[1, :])),
], dtype=np.int64)
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_scaled, vmin=0, annot=True, fmt='d', cmap='viridis')
plt.xlabel('Predict')
plt.ylabel('Ground Truth')
plt.show()
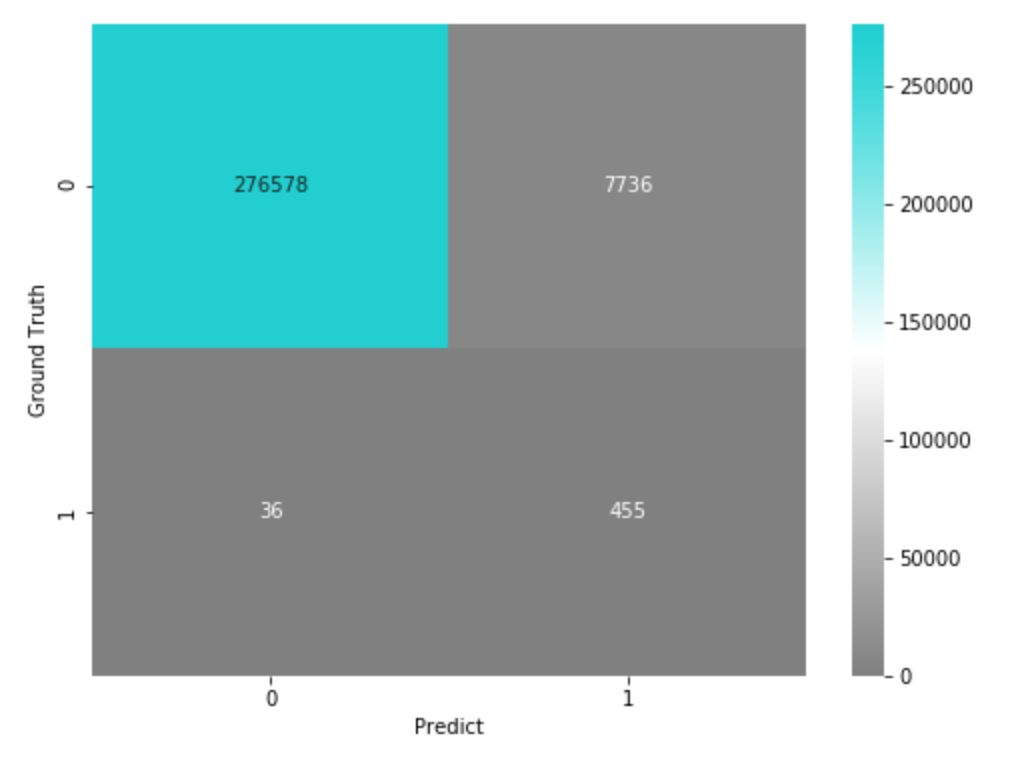
実際の運用時には、このくらいのFalse Positive・False Negativeが発生する、という見立てになります。(なお、より厳密には、先に元データを学習用と評価用に分け、学習側だけをアンダーサンプリングして、評価は元の不均衡比率のまま行う方法が実務的です。本コラムでは簡単のため、均衡化したデータで評価し、その結果を実際の比率にスケールするという簡易的な推定を行っています。)
インパクトで見るモデル評価
ここからが本題です。少し実務向けの設定を仮定して、それぞれの予測結果が損益にどう効くかまで考えてみます。
クレジットカードには盗難保険がついていますよね。不正利用により顧客が失った金額は、こうした盗難保険などの形でクレジットカード会社が負担することになっているそうです。
つまり、不正利用がないと予測したのに実際は不正利用があった場合(False Negative)、不正利用を見逃したことになり、顧客のお金が失われ、結果としてカード会社が負担するコスト\( cost_{fn}(account) \)が発生すると考えられます。
逆に、実際に不正利用されたものを正しく不正利用だと予測でき、失うはずだった金額を防げた場合(True Positive)の効果を、いったん\( benefit_{tp}(account) \)と置きます。
また、不正利用があると予測したのに実際は不正利用がなかった場合(False Positive)、そのアカウントに迷惑をかけることになり、利用停止を解除するコスト\( cost_{fp}(account) \)が発生すると考えます。さらに、不正利用がないと予測して実際にもなかった場合(True Negative)の1アカウントあたり平均利益\( benefit_{tn}(account) \)も置いておきましょう。
このように考えると、損益行列は次のように表せます。
| \( benefit_{tn}(\text{True Negative accounts}) \) | \( cost_{fp}(\text{False Positive accounts}) \) |
| \( cost_{fn}(\text{False Negative accounts}) \) | \( benefit_{tp}(\text{True Positive accounts}) \) |
さらに簡単な設定として、次のように仮定します。
- 利用停止を解除するコストとして、1アカウントあたり平均コスト1万円
- 不正利用を検知できず悪用されてしまったときの負担として、1アカウントあたり平均コスト100万円
本当は、解除まわりの人件費や、悪用されてしまった場合のカード再発行コストなどもあり、こんなにシンプルな話ではないと思いますが、ここでは簡単な設定にしておきます。また、\( benefit_{tn} \)・\( benefit_{tp} \)は、コストは防げるものの利益自体は発生していないので0とします。万円単位で整理すると、以下のように書けます。
- \( benefit_{tn}(account) = 0 \)
- \( cost_{fp}(account) = -1 \times account \)
- \( cost_{fn}(account) = -100 \times account \)
- \( benefit_{tp}(account) = 0 \)
この仮定でモデルの予測結果を損益行列にしてみます。
元記事のコードにはnp.intが使われていますが、NumPy 1.24で削除されたため、現行ではintやnp.int64を使います。以下は修正済みのコードです。
def benefit_tn(account):
return 0 * account
def cost_fp(account):
return -1 * account
# 不正利用を検知できずに悪用されてしまったと考える場合
def cost_fn(account):
return -100 * account
def benefit_tp(account):
return 0 * account
tn, fp, fn, tp = confusion_matrix_scaled.flatten()
bc_matrix = np.array([
[benefit_tn(tn), cost_fp(fp)],
[cost_fn(fn), benefit_tp(tp)],
], dtype=np.int64)
plt.figure(figsize=(7, 5))
sns.heatmap(bc_matrix, annot=True, fmt='d', cmap='viridis')
plt.xlabel('Predict')
plt.ylabel('Ground Truth')
plt.title('Benefit matrix / total = {}'.format(bc_matrix.sum()))
plt.show()
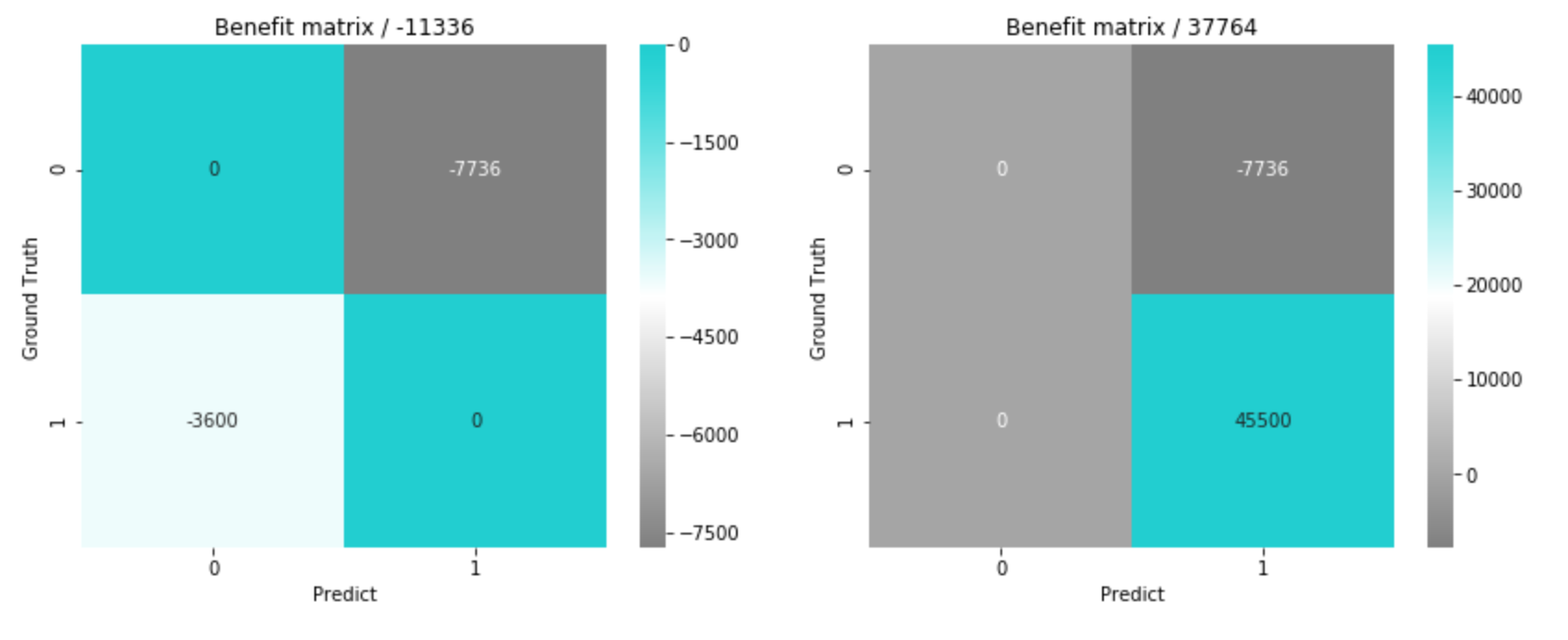
続いて、閾値の最適化です。predictは予測確率が0.5以上でクラス判定しますが、この閾値をどこに設定すればコストを最小化(利益を最大化)できるかを可視化してみます。
# 利益曲線を作る
pred_prob = vote_soft_model.predict_proba(valid_x)[:, 1] # 不正利用である確率
def get_expected_benefit(confusion_matrix):
confusion_matrix_scaled = np.array([
confusion_matrix[0, :]*(len(df[df['Class'] == 0])/sum(confusion_matrix[0, :])),
confusion_matrix[1, :]*(len(df[df['Class'] == 1])/sum(confusion_matrix[1, :])),
], dtype=np.int64)
tn, fp, fn, tp = confusion_matrix_scaled.flatten()
return benefit_tn(tn) + cost_fp(fp) + cost_fn(fn) + benefit_tp(tp)
thresholds = np.linspace(0, 1, 101)
benefits = np.zeros(len(thresholds))
for i, thresh in enumerate(thresholds):
pred_tmp = (pred_prob > thresh).astype(int)
confusion_matrix = metrics.confusion_matrix(valid_y, pred_tmp)
benefits[i] = get_expected_benefit(confusion_matrix)
plt.plot(thresholds, benefits)
plt.xlabel('Threshold')
plt.ylabel('Benefit')
plt.title('Benefit curve')
plt.grid()
plt.show()
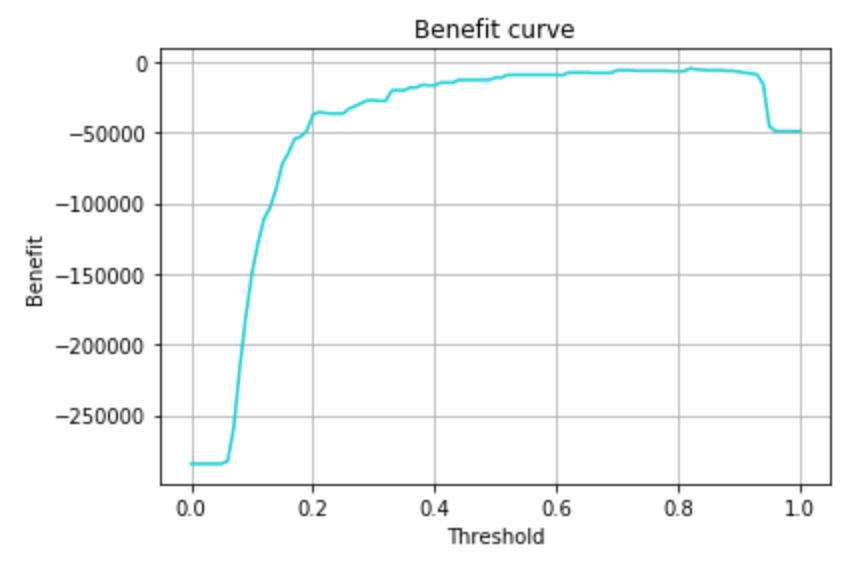
予測確率0.8あたりで利益が最大になりそうです。学習データと検証データの組み合わせを何パターンか試すため、複数回の検証で信頼区間を出し、そのうえで最小コストとなる閾値を求めてみます。
from scipy.stats import mstats
trial_num = 20
thresholds = np.linspace(0, 1, 101)
benefits = np.zeros((trial_num, len(thresholds)))
for trial in tqdm(range(trial_num)):
train_x, valid_x, train_y, valid_y = train_test_split(
data_x_sample, data_y_sample, test_size=0.3)
vote_soft_model.fit(train_x, train_y)
pred_prob = vote_soft_model.predict_proba(valid_x)[:, 1]
for i, thresh in enumerate(thresholds):
pred_tmp = (pred_prob > thresh).astype(int)
confusion_matrix = metrics.confusion_matrix(valid_y, pred_tmp)
benefits[trial, i] = get_expected_benefit(confusion_matrix)
lower, median, upper = mstats.mquantiles(benefits, [0.1, 0.5, 0.9], axis=0)
best_threshold = thresholds[np.argmax(median)]
plt.figure(figsize=(10, 6))
plt.plot(thresholds, median)
plt.fill_between(thresholds, upper, lower, alpha=0.3, linewidth=0)
plt.vlines([best_threshold], benefits.min(), benefits.max(), color='black', linestyles='--')
plt.xlabel('Threshold')
plt.ylabel('Benefit')
plt.title('Benefit curve / interval 0.1--0.9')
plt.grid()
plt.show()
best_threshold # 0.82 付近
試行を繰り返すと、最適な閾値はおよそ0.82付近になりました。
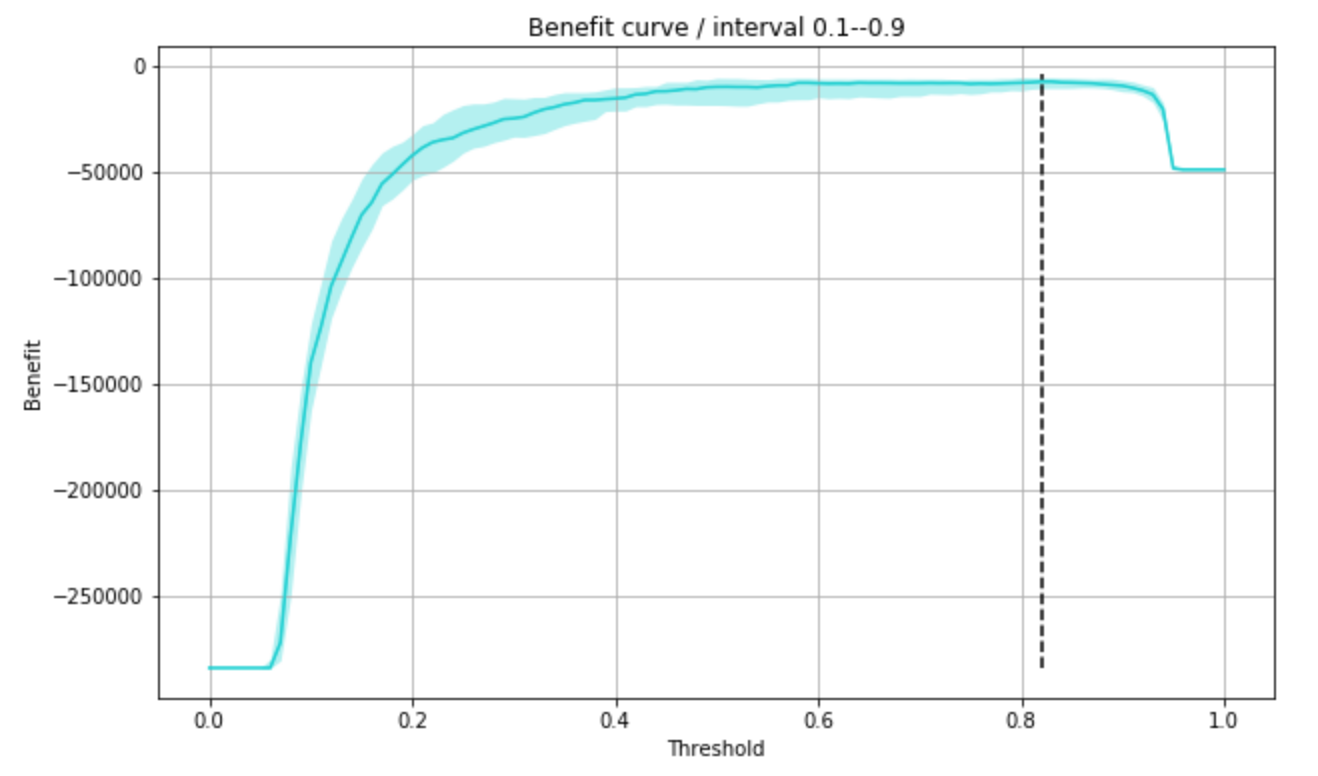
この閾値で再度損益行列を出してみると、今回の仮定の場合では、False Positiveを抑える(Precisionを高めにしておく)方がコストがかからない、という結果になりました。
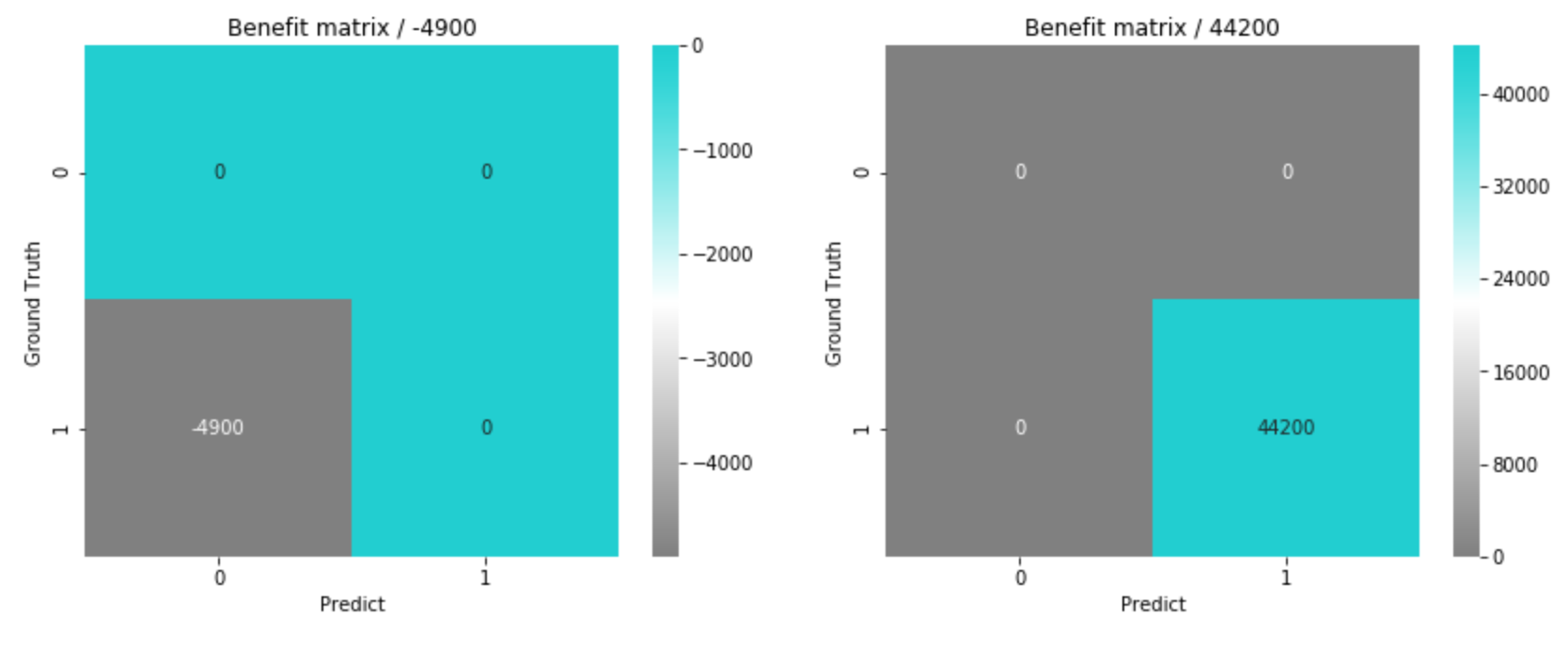
ここで重要なのは、「精度が一番高い閾値(0.5)」と「コストが一番小さい閾値(0.82)」が一致しないという点です。何を最適化すべきかは、精度ではなくビジネス上のコスト構造によって決まります。コストの設定が変われば、最適な閾値も、目指すべきPrecisionとRecallのバランスも変わります。
おまけ:主成分の傾向分析
ついでに、今回のデータは主成分の中身が分かりませんが、どの主成分がクラス判別に効きそうなのか、決定木モデルで傾向を分析してみました。
元記事では決定木の可視化にgraphviz/pydotplusを使っていましたが、現在のscikit-learnにはplot_treeが用意されており、追加ライブラリなしで可視化できます。
train_x, valid_x, train_y, valid_y = train_test_split(
data_x_sample, data_y_sample, test_size=0.3, random_state=0)
decision_tree = tree.DecisionTreeClassifier(max_depth=5, random_state=0)
decision_tree.fit(train_x, train_y)
plt.figure(figsize=(20, 10))
tree.plot_tree(decision_tree, feature_names=cols, filled=True, max_depth=2, fontsize=8)
plt.show()
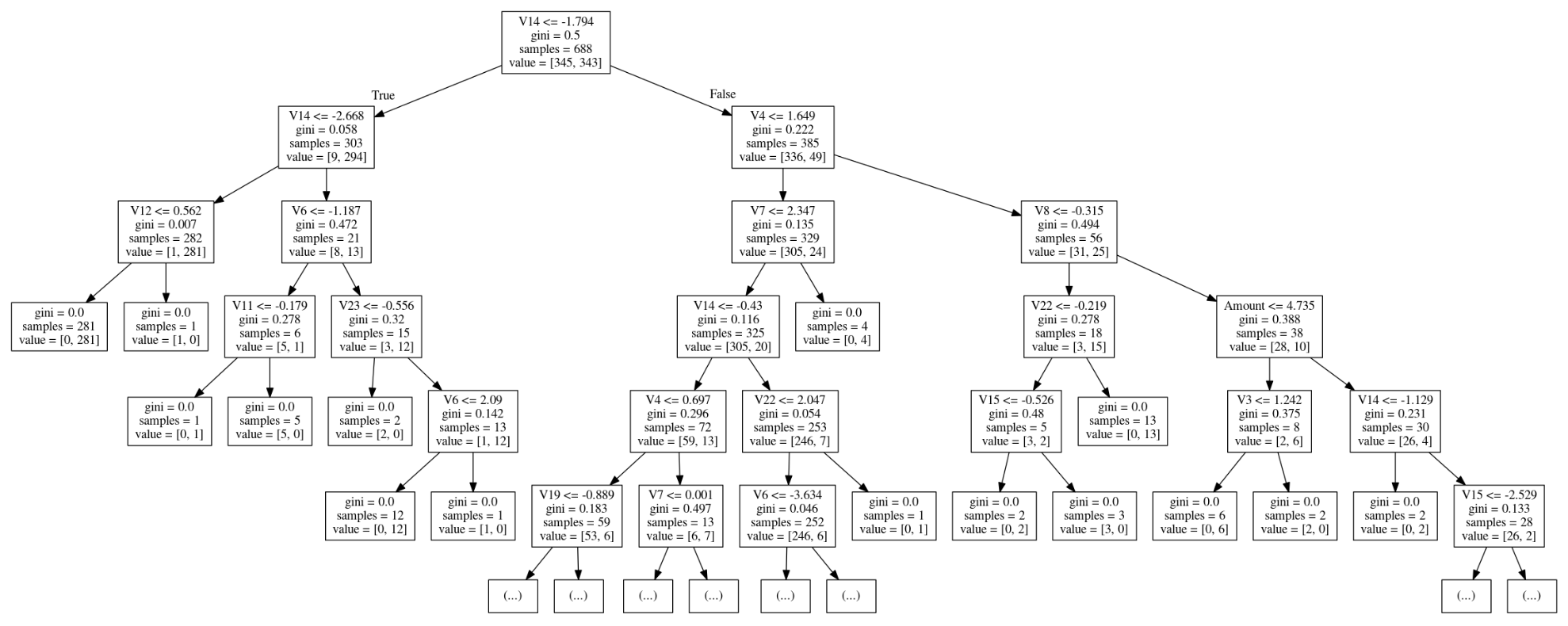
可視化してみると、1つ目の分岐ルール(V14 <= -1.794)でかなり分けられていることが、ジニ係数などから分かります。そこで、この1つ目のルールで切り分けられた集団ごとに、不正利用の比率を確認してみます。
元記事ではsns.factorplotを使っていましたが、現行のseabornではsns.catplotに名称が変更されています。
df_tmp = df.copy()
df_tmp['V14 <= -1.794'] = (df_tmp['V14'] <= -1.794).astype(int)
g = sns.catplot(x='V14 <= -1.794', y='Class', data=df_tmp, kind='bar')
g.set_ylabels('Fraud Probability')
plt.hlines([df_tmp['Class'].sum()/len(df_tmp)], -1, 2, color='black', linestyles='--')
plt.show()
# 各集団の不正利用率
rate_1 = df_tmp[df_tmp['V14 <= -1.794'] == 1]['Class'].mean() # 約0.0485
rate_0 = df_tmp[df_tmp['V14 <= -1.794'] == 0]['Class'].mean() # 約0.00023
print(rate_1, rate_0)
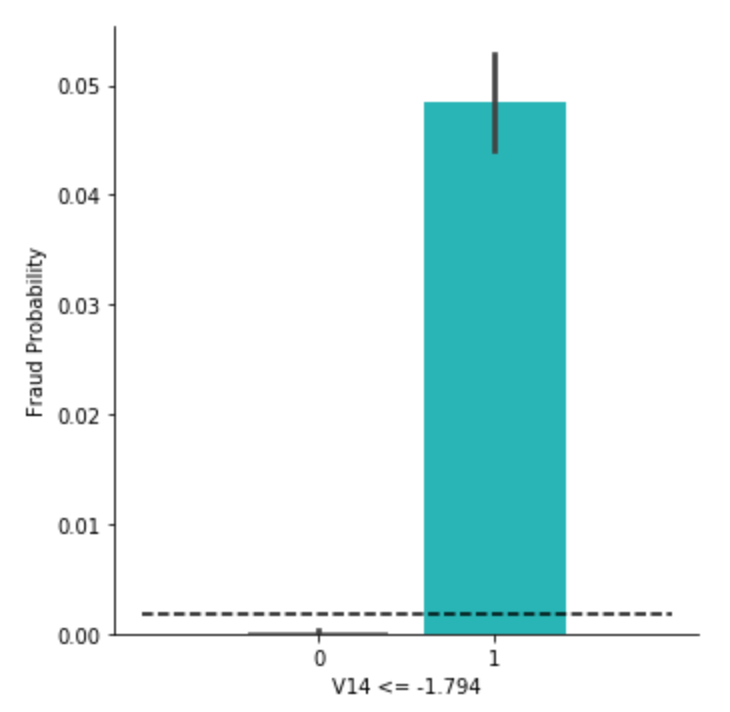
黒の点線は、もともとの全体における不正利用の確率0.00173を指しています。ルールで切り分けた集団ごとに見ると、不正利用率はかなり異なり、V14 <= -1.794を満たす集団では約4.85%、満たさない集団では約0.023%でした。冒頭の相関行列でも、この主成分(V14)は他に比べて絶対値が大きめでした。意外と、生データの段階で不正利用かどうかを判断しやすい項目があり、それが自然とこの主成分にまとめられたのかもしれません。
その後の発展・最新動向(2026年時点)
元記事の執筆以降も、不正検知の分野は大きく進展しています。実務の観点で押さえておきたいポイントを整理します。
- 被害の拡大と対策の重要性: 日本クレジット協会の統計によると、2024年のクレジットカード不正利用被害額は約555億円と過去最高を更新しました。不正検知の精度向上は、依然として喫緊の経営課題です。
- 不均衡データへの対処の発展: 本コラムではアンダーサンプリングを使いましたが、少数クラスを人工的に水増しするSMOTEやその派生手法、損失関数で少数クラスを重視するクラス重み付け(cost-sensitive learning)など、選択肢が広がりました。本コラムで扱ったのは主に「コストに基づいてモデルを評価し、閾値を最適化する」アプローチですが、これをさらに進めて、学習時の損失関数にコストやクラス重みを組み込むcost-sensitive learningという考え方もあります。
- 手法の高度化: 勾配ブースティング(XGBoost、LightGBMなど)は今でも不正検知の主力ですが、取引どうしの関係性をグラフとして捉えるグラフニューラルネットワーク(GNN)や、正常データのパターンから外れるものを検知する異常検知(Isolation Forest、オートエンコーダなど)も活用されています。
- リアルタイム性と説明可能性: 決済の現場では、取引が成立する前のミリ秒単位での判定が求められます。同時に、「なぜ不正と判定したのか」の説明可能性も重要で、別コラムで紹介したSHAPのような手法が、不正判定の根拠提示に使われています。機械学習による判定と、従来のルールベースの判定を組み合わせるハイブリッドな運用も一般的です。
- 変わらない本質: 手法は進化しましたが、本コラムの主題である「精度ではなく、ビジネスのコスト構造に照らしてモデルを評価し、閾値を決める」という考え方は、まったく古びていません。むしろ、AIを実務で使ううえで最も大切な視点の一つだと、改めて感じます。
まとめ
今回は、ビジネスの意思決定者に向けて、「インパクトとしてのモデル評価」を念頭に取り組んでみました。損益行列のようなインパクト目線での効果を示すことで、意思決定者はモデルのビジネス経済的な効果を適切に理解し、より賢明な判断を下すことができます。
機械学習研究者ではなく、私のようにビジネスでデータサイエンスを活用する立場であれば、「この施策でこれだけの効果が得られます」とビジネス効果を把握して示せるスキルも、あわせて持っておくことが重要だと思います。
参考文献
- Credit Card Fraud Detection データセット(Kaggle): https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
- imbalanced-learn 公式ドキュメント: https://imbalanced-learn.org/stable/
- scikit-learn 公式ドキュメント(VotingClassifier): scikit-learn公式
- 一般社団法人日本クレジット協会「クレジットカード不正利用被害額の発生状況」: https://www.j-credit.or.jp/information/statistics/
- Provost & Fawcett『戦略的データサイエンス入門』(オライリー・ジャパン、損益行列によるモデル評価の考え方の参考)