※本コラムは、以前に個人ブログとして公開していた内容を、加筆・再構成のうえ掲載しております。技術的な内容は執筆当時のものであり、現在とは異なる場合がございます。
こんにちは。Anagraftの伊藤です。
今日では、自然言語処理(NLP)の分野で、文章を数値表現に変換するためのさまざまな手法が存在します。これらの手法は、テキストデータを機械学習アルゴリズムに適用する際に重要な役割を果たしており、機械翻訳、感情分析、トピック分析、文書分類などのタスクに広く利用されています。
今回は文章ベクトルを計算する手法に焦点を当てて、その中でもSCDV(Sparse Composite Document Vectors)という手法について紹介し、他の文章ベクトル手法との比較を行います。
なお、元記事の執筆は2018年で、当時はWord2Vecをベースとした文章ベクトルが主流でした。その後、文埋め込みの世界はBERT以降のTransformerベースの手法へと大きく移り変わっています。本コラムのコード例は現行のライブラリ(gensim 4系など)で動くよう修正したうえで、記事の後半でこの最新動向にも触れます。

目次
Sparse Composite Document Vectors: SCDVについて
SCDVは、2017年にMicrosoft Researchのチームより提案された、文書内の単語の分散表現と頻度情報を利用して文章をベクトル化する手法です。論文は以下です。
- Mekala, D., et al. (2017). SCDV: Sparse Composite Document Vectors using soft clustering over distributional representations. EMNLP 2017
文章ベクトルを取得する手法は他にもDoc2Vecなど色々ありますが、論文内で文章ベクトルを用いたマルチクラス分類・マルチラベル分類を比較したところ、他の文章ベクトル手法よりも高い分類精度が出せたとされています。つまりそれだけ、文章の特徴の偏りをうまく捉え、異なる文書を異なるものとしてベクトル表現できている手法ということになります。
SCDVのアルゴリズムの流れは以下のようになっており、計算方法自体はそこまで難しくありません。

まず、文章データから得られる全単語について、Word2Vecベクトルとidf値を計算しておきます。この単語ベクトルを混合ガウスモデル(GMM)でKクラスにソフトクラスタリングし、各単語ベクトルが各クラスタに属する予測確率を単語ベクトルに掛けて連結することで、「単語ベクトルの次元数 × クラスタ数」へと次元を広げます。これにidf値を掛けたものが、単語ごとの Word-topics vector になります。最後に、これを文章を構成する単語について平均し、小さな値をゼロに切り捨ててスパース化したものを、その文章のベクトルとして扱います。
SCDVおよび各種文章ベクトル手法の実装
それでは、文章ベクトルSCDVと、その他の古くからある手法を実装してみて、各文章ベクトルがどのような様子か可視化してみます。具体的には、BoW・tf-idf・Averaged-Word2Vec・Doc2Vec・SCDVをそれぞれ実装し、これらをt-SNEで2次元に圧縮してプロットして確認してみます。
文章データには、元記事と同じく20 Newsgroupsのコーパスを使います。ただし、20クラスすべてを扱うと時間がかかるので、5クラス分だけ取得することにします。
元記事の執筆時点ではgensim 3系を使っていましたが、2021年にリリースされたgensim 4系では、Word2Vec・Doc2VecのAPIが変更されています(size→vector_size、iter→epochs、wv.index2word→wv.index_to_key など)。本コラムのコードはgensim 4系に合わせて修正しています。
import re
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import seaborn as sns
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn import datasets, manifold, mixture, model_selection
from gensim.models import Word2Vec
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from xgboost import XGBClassifier
# 適当にトピックカテゴリを選択
categories = [
'alt.atheism',
'comp.graphics',
'rec.sport.baseball',
'sci.space',
'talk.politics.guns'
]
train = datasets.fetch_20newsgroups(subset='train', categories=categories)
train.data = np.array(train.data, dtype=object)
# それぞれ含まれる文章数をカウント
for i, c in enumerate(categories):
indices = np.where(train.target == i)
print(c + ':\t{}'.format(len(train.data[indices])))
alt.atheism: 480
comp.graphics: 584
rec.sport.baseball: 597
sci.space: 593
talk.politics.guns: 546
合計2800件の文章データを取得しました。
続いて、各種手法で用いる定数パラメータとアナライザーを準備します。アナライザーは、いずれの手法もまず文章を単語に分解する必要があるため、入力された文章を単語へ分解する関数です。ストップワードは本来もっと多く入れるべきですが、ひとまずこのくらいにしておきます。
# BoW, tf-idf, average Word2Vec, Doc2Vec, SCDV
features_num = 200
min_word_count = 10
context = 5
downsampling = 1e-3
epoch_num = 10
# Analyzer
def analyzer(text):
stop_words = ['i', 'a', 'an', 'the', 'to', 'and', 'or', 'if', 'is', 'are', 'am', 'it', 'this', 'that', 'of', 'from', 'in', 'on']
text = text.lower() # 小文字化
text = text.replace('\n', '') # 改行削除
text = text.replace('\t', '') # タブ削除
text = re.sub(re.compile(r'[!-\/:-@[-`{-~]'), ' ', text) # 記号をスペースに置き換え
text = text.split(' ') # スペースで区切る
words = []
for word in text:
if (re.compile(r'^.*[0-9]+.*$').fullmatch(word) is not None): # 数字が含まれるものは除外
continue
if word in stop_words: # ストップワードに含まれるものは除外
continue
if len(word) < 2: # 1文字、0文字(空文字)は除外
continue
words.append(word)
return words
BoW
まずは一番基礎的なBoW(Bag of Words)で文章の特徴量を表した場合についてです。この辺りはsklearn.feature_extraction.textに関数が用意されているので、積極的に使っていきます。
# BoW
corpus = train.data
count_vectorizer = CountVectorizer(analyzer=analyzer, min_df=min_word_count, binary=True)
bows = count_vectorizer.fit_transform(corpus)
bows.shape # (2800, 5445)
# t-SNEで圧縮して可視化
tsne_bow = manifold.TSNE(n_components=2, random_state=42).fit_transform(bows.toarray())
df_tsne_bow = pd.DataFrame({
'x': tsne_bow[:, 0],
'y': tsne_bow[:, 1],
'category': train.target,
})
df_tsne_bow.plot.scatter(x='x', y='y', c='category', colormap='viridis', figsize=(7, 5), s=20)
plt.show()
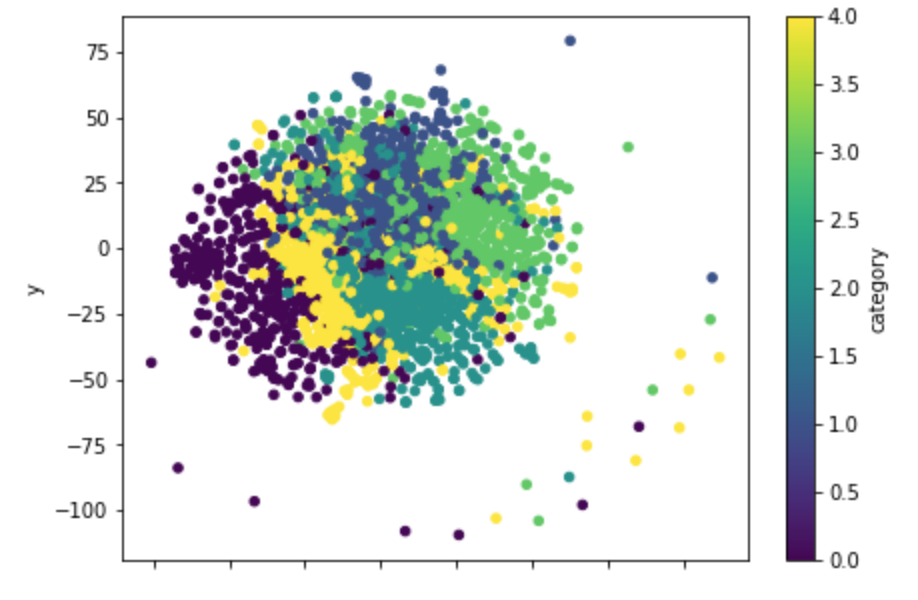
2次元に圧縮した後の可視化ですが、この図では、あまり分かれてくれていないように見えます。
tf-idf
次にtf-idfです。これもsklearn.feature_extraction.textに関数が用意されていますので、すぐ作成できます。
# tf-idf
corpus = train.data
tfidf_vectorizer = TfidfVectorizer(analyzer=analyzer, min_df=min_word_count)
tfidfs = tfidf_vectorizer.fit_transform(corpus)
tfidfs.shape # (2800, 5445)
# t-SNEで圧縮して可視化
tsne_tfidf = manifold.TSNE(n_components=2, random_state=42).fit_transform(tfidfs.toarray())
df_tsne_tfidf = pd.DataFrame({
'x': tsne_tfidf[:, 0],
'y': tsne_tfidf[:, 1],
'category': train.target,
})
df_tsne_tfidf.plot.scatter(x='x', y='y', c='category', colormap='viridis', figsize=(7, 5), s=20)
plt.show()
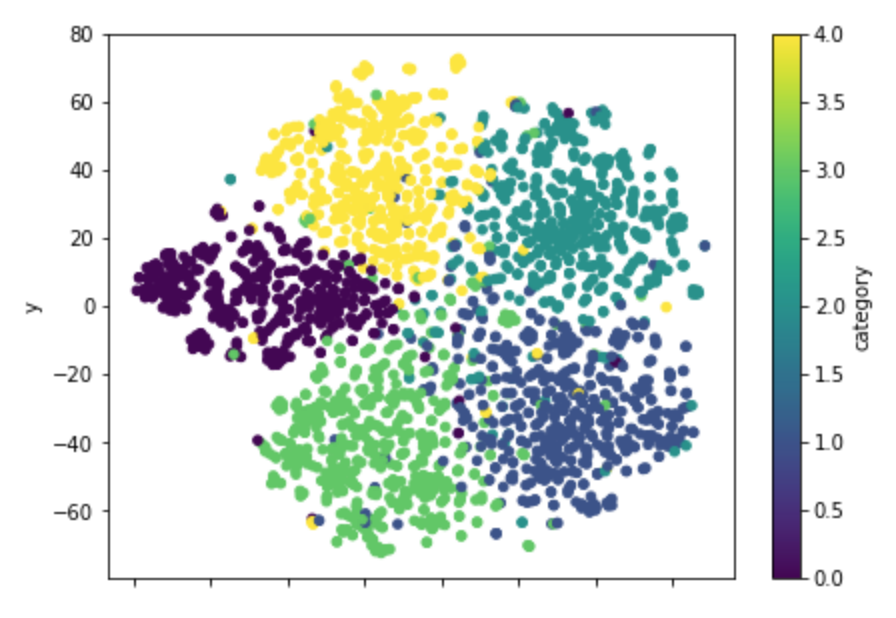
こちらは先ほどのBoWと比べると、綺麗に分かれてくれているように見えます。
Averaged-Word2Vec
Word2Vecは単語ベクトルの手法ですが、文章に含まれる単語をこのベクトルで計算して平均をとるなどして一つのベクトルに集約することで、文章ベクトルとする方法もよく利用されます。Word2Vecはgensimで簡単に学習でき、ベクトルへの変換が可能です。今回はWord2Vecモデルで表される単語ベクトルの平均(Average)をとって文章ベクトルとしました。
# Averaged-Word2Vec
corpus = [analyzer(text) for text in train.data]
word2vecs = Word2Vec(
sentences=corpus, epochs=epoch_num, vector_size=features_num,
min_count=min_word_count, window=context, sample=downsampling, seed=42,
)
def avg_vector(text):
vecs = [word2vecs.wv[w] for w in analyzer(text) if w in word2vecs.wv.key_to_index]
if len(vecs) == 0: # 語彙に含まれる単語が無い場合はゼロベクトル
return np.zeros(features_num, dtype=np.float32)
return np.mean(vecs, axis=0)
avg_word2vec = np.array([avg_vector(text) for text in train.data])
avg_word2vec.shape # (2800, 200)
# t-SNEで圧縮して可視化
tsne_avg_word2vec = manifold.TSNE(n_components=2, random_state=42).fit_transform(avg_word2vec)
df_tsne_avg_word2vec = pd.DataFrame({
'x': tsne_avg_word2vec[:, 0],
'y': tsne_avg_word2vec[:, 1],
'category': train.target,
})
df_tsne_avg_word2vec.plot.scatter(x='x', y='y', c='category', colormap='viridis', figsize=(7, 5), s=20)
plt.show()
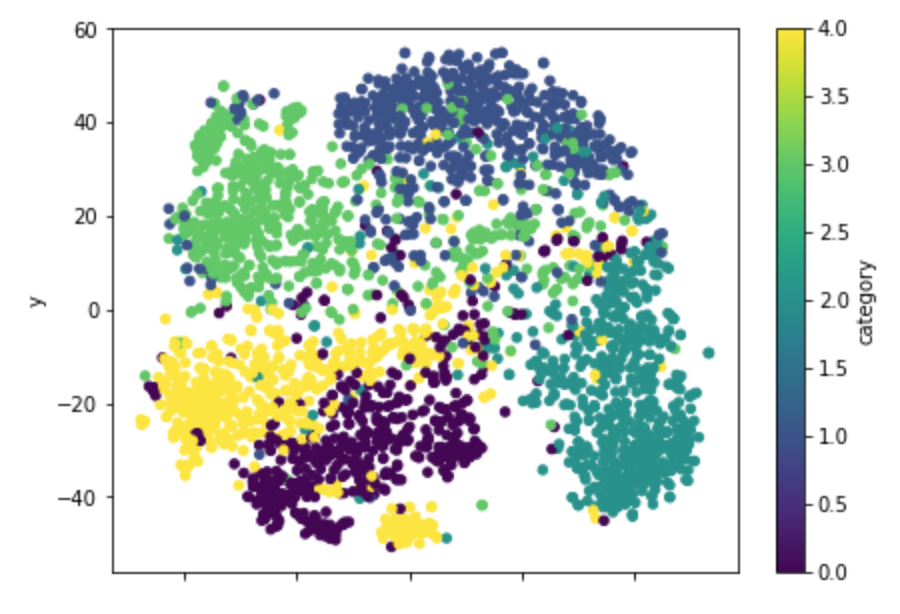
これも割と文章のラベルごとに分かれてくれているようです。同じクラスでも、さらに別の集団として捉えているようなものも見られます。
Doc2Vec
Doc2Vecも試してみます。こちらもgensimから利用可能です。
# Doc2Vec
corpus = [TaggedDocument(words=analyzer(text), tags=[i]) for i, text in enumerate(train.data)]
doc2vec_model = Doc2Vec(
documents=corpus, dm=1, epochs=epoch_num, vector_size=features_num,
min_count=min_word_count, window=context, sample=downsampling, seed=42
) # dm == 1 -> dmpv, dm != 1 -> DBoW
doc2vecs = np.array([doc2vec_model.infer_vector(analyzer(text)) for text in train.data])
doc2vecs.shape # (2800, 200)
# t-SNEで圧縮して可視化
tsne_doc2vec = manifold.TSNE(n_components=2, random_state=42).fit_transform(doc2vecs)
df_tsne_doc2vec = pd.DataFrame({
'x': tsne_doc2vec[:, 0],
'y': tsne_doc2vec[:, 1],
'category': train.target,
})
df_tsne_doc2vec.plot.scatter(x='x', y='y', c='category', colormap='viridis', figsize=(7, 5), s=20)
plt.show()
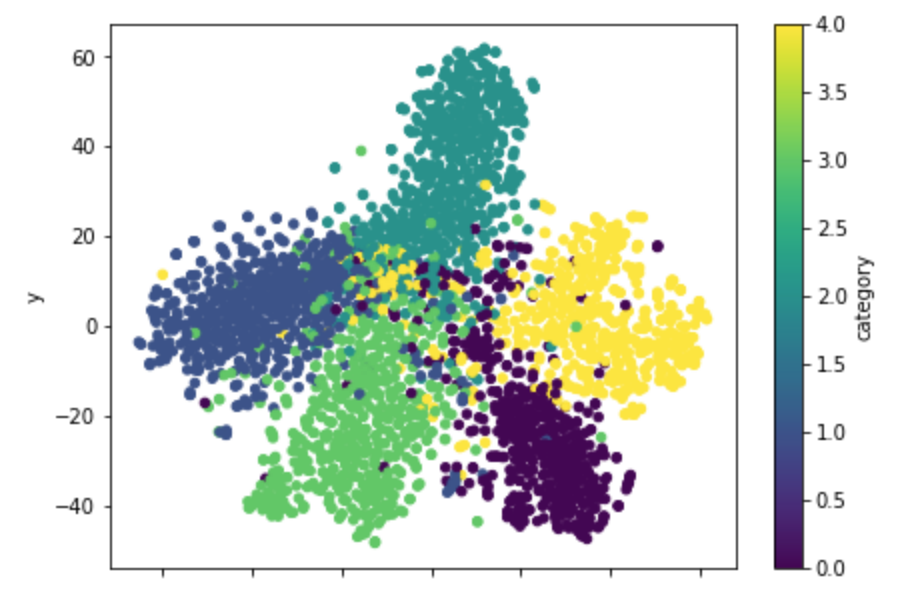
他の分散表現もそうですが、うまく分かれてくれていなさそうな文章が中心あたりに一定数集まっているようにも見えます。
SCDV
ここまで、様々な文章ベクトルについて見てきました。SCDVについても同様にやってみます。実装は論文の公式リポジトリが公開されていますので、こちらも参考にしながら書いてみます。
まずは、すべての単語ベクトルを混合ガウスモデルで学習してソフトクラスタリングします。論文では、このクラスタ数を変えたときに分類モデルの精度がどう変化するかを調査しており、クラスタ数が60以上ではあまり変化がないように見えますので、ここではクラスタ数を60としました。他、sparsityは4%、ベクトル次元数は200にしています。
word_vectors = word2vecs.wv.vectors
clusters_num = 60
gmm = mixture.GaussianMixture(n_components=clusters_num, covariance_type='tied', max_iter=50, random_state=42)
gmm.fit(word_vectors)
次に、Word-topics vectorを作成し、単語ごとに単語ベクトルと各クラスタの予測確率、idf値を掛け合わせます。
idf_dic = dict(zip(tfidf_vectorizer.get_feature_names_out(), tfidf_vectorizer.idf_))
assign_dic = dict(zip(word2vecs.wv.index_to_key, gmm.predict(word_vectors)))
soft_assign_dic = dict(zip(word2vecs.wv.index_to_key, gmm.predict_proba(word_vectors)))
word_topic_vecs = {}
for word in assign_dic:
word_topic_vecs[word] = np.zeros(features_num*clusters_num, dtype=np.float32)
for i in range(0, clusters_num):
try:
word_topic_vecs[word][i*features_num:(i+1)*features_num] = word2vecs.wv[word]*soft_assign_dic[word][i]*idf_dic[word]
except:
continue
出来上がったWord-topics vectorを用いて、文章ごとにベクトルを作成します。
scdvs = np.zeros((len(train.data), clusters_num*features_num), dtype=np.float32)
a_min = 0
a_max = 0
for i, text in enumerate(train.data):
tmp = np.zeros(clusters_num*features_num, dtype=np.float32)
words = analyzer(text)
for word in words:
if word in word_topic_vecs:
tmp += word_topic_vecs[word]
norm = np.sqrt(np.sum(tmp**2))
if norm > 0:
tmp /= norm
a_min += min(tmp)
a_max += max(tmp)
scdvs[i] = tmp
p = 0.04
a_min = a_min*1.0 / len(train.data)
a_max = a_max*1.0 / len(train.data)
thres = (abs(a_min)+abs(a_max)) / 2
thres *= p
scdvs[abs(scdvs) < thres] = 0
scdvs.shape # (2800, 12000)
これを同様にt-SNEで圧縮して可視化すると以下のような感じになります。
tsne_scdv = manifold.TSNE(n_components=2, random_state=42).fit_transform(scdvs)
df_tsne_scdv = pd.DataFrame({
'x': tsne_scdv[:, 0],
'y': tsne_scdv[:, 1],
'category': train.target,
})
df_tsne_scdv.plot.scatter(x='x', y='y', c='category', colormap='viridis', figsize=(7, 5), s=20)
plt.show()
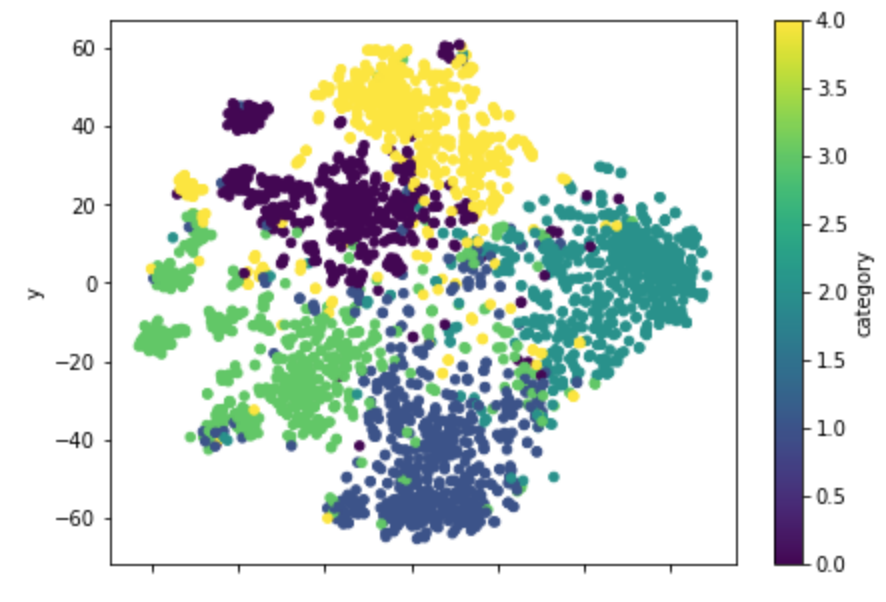
同じクラス内でも、さらにちらほらと塊の島のようなものが出来上がっており、より細かく特徴的な文章の分類を表現できているような気がします。やはり微妙にうまく分かれてくれない文章もちらほら見られますが、もともと難しい文章については同様に難しいのでしょう。
分類モデルによる比較
さて、前章で様々な文章ベクトルを生成することができました。これを分類モデルに入れて学習させ、精度を確認してみます。論文ではSVMで調べられていますが、今回はXGBoostを使ってみました。
元記事では結果をpandas.DataFrame.appendでまとめていましたが、このメソッドはpandas 2.0で削除されました。以下のコードはリストに結果を貯めて最後にpd.DataFrameを作る形に修正しています。
model = XGBClassifier()
scoring = ['accuracy']
cv_trial_num = 8
records = []
datasets_to_compare = [
('BoW', bows.toarray()),
('tfidf', tfidfs.toarray()),
('avg_Word2Vec', avg_word2vec),
('Doc2Vec', doc2vecs),
('SCDV', scdvs),
]
# XGBoostは目的変数が0始まりの連番である必要があるためそのまま利用
for name, X in datasets_to_compare:
cv_rlts = model_selection.cross_validate(
model, X, train.target, scoring=scoring, cv=cv_trial_num, return_train_score=True)
for i in range(cv_trial_num):
records.append({
'name': name,
'train_accuracy': cv_rlts['train_accuracy'][i],
'valid_accuracy': cv_rlts['test_accuracy'][i],
'time': cv_rlts['fit_time'][i],
})
df_compare = pd.DataFrame(records)
plt.figure(figsize=(12, 5))
sns.boxplot(data=df_compare, y='name', x='valid_accuracy', orient='h', palette='viridis', linewidth=0.5, width=0.5)
plt.grid()
plt.title('validation accuracy')
plt.show()
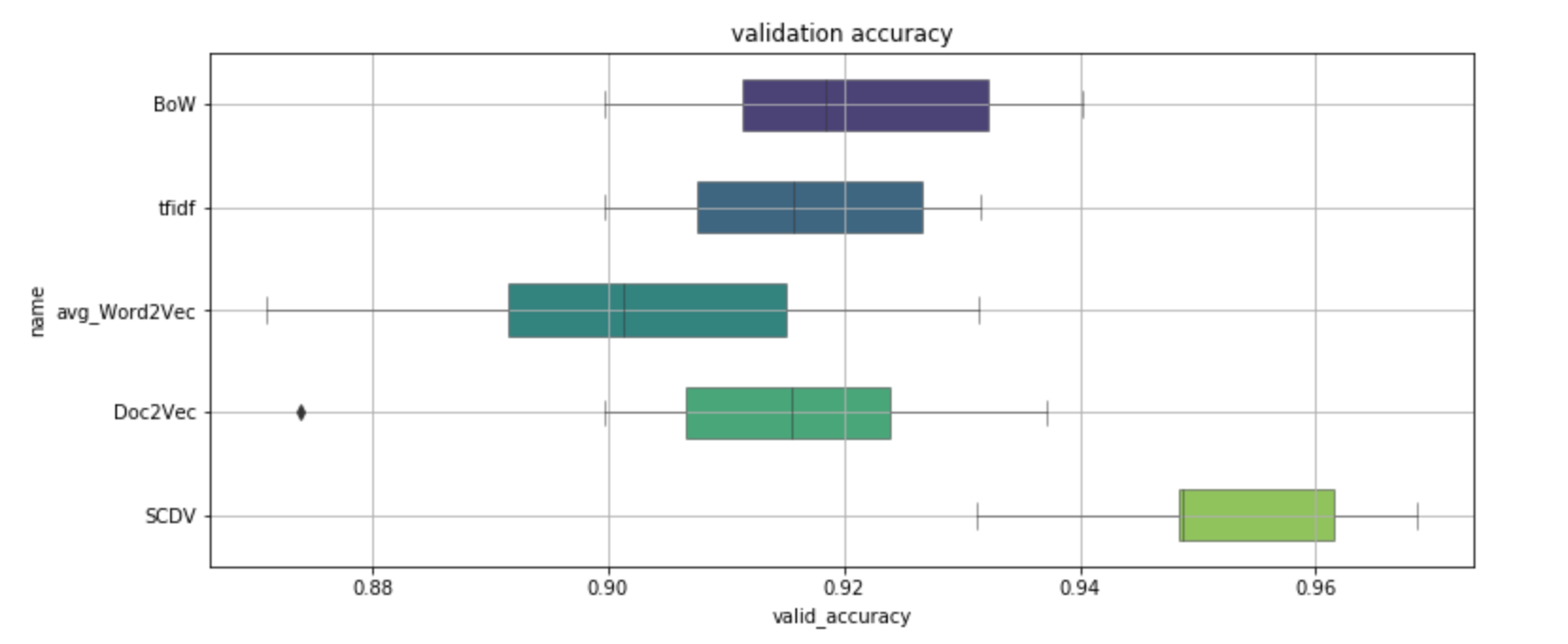
横軸が分類精度を表しており、SCDVだけ精度が頭一つ抜けている様子が分かります。誤差でたまにBoWやDoc2Vecに劣ることもあるようですが、全体的には精度が上がっているように見受けられます。
BoWが割と良いというのが意外でした。可視化ではだいぶ潰されてしまったように見えましたが、潰されたベクトルに良い感じの軸があったのかもしれません。
その後の発展・最新動向(2026年時点)
元記事を執筆した2018年当時、文章ベクトルといえばWord2VecやDoc2Vecをベースとした手法が主流で、SCDVもその系譜にある手法でした。それから数年で、文埋め込み(文章をベクトルにする技術)の世界はTransformerベースの手法へと大きく移り変わりました。実務で文埋め込みを扱う際に知っておきたいポイントを整理します。
- BERT以降のTransformerベースへ: 2018年末に登場したBERTを皮切りに、文脈を踏まえた埋め込みが一般化しました。特に、文同士の意味的な近さを測れるよう調整されたSentence-BERT(SBERT)以降、文埋め込みは「文の意味をベクトルの近さで表す」精度が大きく向上しました。Word2Vec系は単語の意味を固定的に捉えるのに対し、Transformerベースは同じ単語でも文脈によって異なるベクトルを与えられる点が大きな違いです。
- 埋め込みモデルの多様化: 現在は、OpenAIのtext-embedding-3シリーズのようなAPI型のモデルから、BGE-M3、E5、GTEといった高性能なオープンソースモデルまで、多くの選択肢があります。これらの性能はMTEB(Massive Text Embedding Benchmark)などで比較されており、多言語・日本語に強いモデルも増えています。日本語に特化した国産の埋め込みモデルも登場しています。
- RAGの基盤技術としての重要性: 文埋め込みは、生成AI(LLM)に社内文書などの知識を参照させるRAG(検索拡張生成)の中核技術になりました。質問と文書を同じベクトル空間に埋め込み、意味的に近い文書を検索して回答に活用するという仕組みで、文埋め込みの品質がそのままRAGの精度を左右します。文章をベクトル化するという本コラムのテーマは、生成AI時代になってむしろ実務上の重要性を増しています。
- SCDVの位置づけ: では、SCDVのような手法はもう不要かというと、必ずしもそうではありません。Transformerベースのモデルは高精度な反面、ローカルで大きなモデルを動かす場合は計算コストやGPU環境が論点になり、API型のモデルを使う場合は利用料金や外部サービスへの依存が論点になるなど、扱うにはそれなりの準備が必要です。一方、SCDVやtf-idfのような軽量な手法は、CPUだけで高速に動き、結果の解釈もしやすいという利点があります。データ量が限られる場合や、まず手早くベースラインを作りたい場合には、今でも十分に実用的な選択肢です。本コラムの比較実験で「BoWが意外と健闘した」ように、最先端の手法が常に最適とは限らない、というのは現在でも変わらない教訓だと思います。
まとめ
今回は、文章を数値表現に変換する「文章ベクトル」について、特にSCDVという手法に焦点を当て、その実装方法を紹介しました。SCDVは、単語の分散表現とソフトクラスタリングを組み合わせて文書をベクトル化することで、意味的な情報を豊かに表現できる利点があります。
また、他の文章ベクトル手法としてBoW、tf-idf、Word2Vec、Doc2Vecを挙げ、それらとSCDVの比較を行いました。論文と同様、今回も20 Newsgroupsコーパスで分類精度の向上が見られました。
最適な手法は、扱うタスクやデータによって異なるため、使い分けることが重要です。これは、選択肢がTransformerベースの埋め込みまで広がった現在でも変わりません。実装もそれほど難しくありませんので、データに対して様々な文章ベクトルを試して判断すると良いと思います。
参考文献
- Mekala, D., et al. (2017). SCDV: Sparse Composite Document Vectors using soft clustering over distributional representations. EMNLP 2017
- SCDV 公式リポジトリ(GitHub): https://github.com/dheeraj7596/SCDV
- gensim 公式: 3.x から 4.x への移行ガイド: Migrating from Gensim 3.x to 4
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP 2019
- MTEB: Massive Text Embedding Benchmark: https://huggingface.co/spaces/mteb/leaderboard
- OpenAI「Embeddings」公式ガイド: https://platform.openai.com/docs/guides/embeddings
- BAAI「BGE-M3」(多言語埋め込みモデル): https://huggingface.co/BAAI/bge-m3