※本コラムは、以前に個人ブログとして公開していた内容を、加筆・再構成のうえ掲載しております。技術的な内容は執筆当時のものであり、現在とは異なる場合がございます。
こんにちは。Anagraftの伊藤です。
新型コロナウイルス(COVID-19)の感染者数が日々急速に増えていた時期がありました。 こういった感染症流行の状況変化に対して一歩でも先に対策を講じるために、今後の流行の流れを予測することはとても重要です。
そのためのツールとして、今回は、感染症の広がりを予測するモデルおよびその実装を紹介します。 具体的には、SIRモデルを用いて新型コロナウイルスの感染者数の予測を試みました。 SIRモデルは感染症流行の様子を表すために広く使われるモデルです。 このモデルを使って新型コロナウイルスの流行を予測し、最尤推定とベイズ推定の手法を用いてパラメータを推定してみます。

SIRモデル
SIRモデルは感染症の流行(拡大)の振る舞いを表すための決定論的なモデルで、感染症の流行と共に人口が「Susceptible(感染可能)」、「Infected(感染者)」、「Recovered(回復者)」の3つの状態に変化することを表します。 実は1927年から登場した歴史のあるモデルでもあります。 詳細は以下のとおりです。
主な活用領域はやはり、ある人々の集団の中でインフルエンザや麻疹などの感染者数がどのように流行に乗り、やがて落ち着くのかといった、疫学的な関心が主流です。 一方で、一部ではTwitterなどのSNS上の流行がどのようにバズっていき、やがて落ち着くのかといったものの調査にも応用されることがあるようです。
SIRモデルの基本的な微分方程式は以下のとおりです。
\( \frac{dS}{dt} = -\beta \frac{S \cdot I}{N} \)
\( \frac{dI}{dt} = \beta \frac{S \cdot I}{N} – \gamma I \)
\( \frac{dR}{dt} = \gamma I \)
ここで、\( S \)は感染可能人口、\( I \)は感染者数、\( R \)は回復者数、\( N \)は総人口、\( \beta \)は感染率、\( \gamma \)は除去率(回復率)です。 感染率\( \beta \)は、感染可能な人が感染者と接触した際にどの程度の確率で感染するかを表すパラメータであり、除去率\( \gamma \)は感染者がどの程度の速度で回復(もしくは除去)されるかを表すパラメータです。
最尤法によるパラメータ推定と予測
SIRモデルのパラメータの推定は、オーソドックスには最尤推定が用いられるようです。 まずはコロナ感染者数のデータから、SIRモデルのパラメータを最尤推定で求め、今後の流行の様子を推定することにします。
都道府県別のコロナ感染者数のデータは以下を利用しました。(2020/04/23時点)
https://github.com/kaz-ogiwara/covid19
実際に読み込むデータは上記リポジトリのうちのprefectures.csvです。
都道府県別に、感染者数、回復者数、死亡者数が時系列で格納されています。
このデータで、I=感染者数、R=回復者数+死亡者数として、流行を予測します。
SIRモデルの定義と最尤推定の実装
SIRモデルおよび尤度関数は、scipyのodeintやminimizeを使って、以下のように実装できます。
from numpy import inf
import numpy as np
from scipy.optimize import minimize
from scipy.integrate import odeint
def sir(y, t, beta, gamma):
dydt = np.zeros(3)
dydt[0] = - beta * y[0] * y[1] / (y[0] + y[1] + y[2]) # dS/dt
dydt[1] = beta * y[0] * y[1] / (y[0] + y[1] + y[2]) - gamma * y[1] # dI/dt
dydt[2] = gamma * y[1] # dR/dt
return dydt
def estimate(target_pred_var, init_state, beta, gamma):
sol = odeint(sir, init_state, np.arange(0, len(target_pred_var)), args=(beta, gamma))
return sol
def loss(x, init_state, target_pred_var):
beta, gamma = x[0], x[1]
sol = estimate(target_pred_var, init_state, beta, gamma)
return np.sum((sol[:, 1] - target_pred_var) ** 2)
def optimize(init_state, target_pred_var):
result = minimize(loss, x0=[0.001, 0.001], args=(init_state, target_pred_var),
method="Nelder-Mead")
return result
def prediction(result, n_pred, init_state):
beta = result.x[0]
gamma = result.x[1]
sol = estimate(np.zeros(n_pred), init_state, beta, gamma)
return sol
ここでは、SIRモデルの微分方程式をodeintで数値的に解き、感染者数の時系列データとの二乗誤差を最小化することで、感染率\( \beta \)と除去率\( \gamma \)を推定しています。
東京都のデータによる最尤推定
たとえば、東京都の感染者数のデータを使い、パラメータの初期値を設定して、以下のように最適化を実行すると、パラメータを推定することができます。
df_tmp = df.reset_index()
df_tmp['dt'] = df_tmp['dt'].astype('str')
df_tmp['dt2'] = df_tmp['dt'].apply(lambda x: dt.strptime(x, '%Y%m%d'))
target_pred_var = df_tmp['infected'].values
target_pred_var_r = df_tmp['recovered'].values
I = target_pred_var
R = target_pred_var_r
N = 14000000
S = N - I - R
init_state = [S[0], I[0], R[0]]
result = optimize(init_state, target_pred_var)
print(result)
推定結果の例は以下のとおりです。
final_simplex: (array([[1.98561299e-01, 1.39422106e-01],
[1.98561055e-01, 1.39421706e-01],
[1.98563439e-01, 1.39424393e-01]]),
array([106399.61884819, 106399.61886498, 106399.61935616]))
fun: 106399.61884819488
message: 'Optimization terminated successfully.'
nit: 89
nfev: 178
status: 0
success: True
x: array([0.19856129, 0.13942211])
x[0]が感染率、x[1]が除去率です。
予測結果の可視化
実際のデータおよび推定されたパラメータを使って、その後の流行(感染者数の推移)を可視化すると、以下のようになりました。
n_pred = 50
t_max = len(target_pred_var) + n_pred
dt = np.arange(0, t_max)
beta = result.x[0]
gamma = result.x[1]
dates = data.index.tolist()
for i in range(n_pred):
d = d + datetime.timedelta(days=1)
dates.append(d)
sol = odeint(sir, init_state, dt,
args=(beta, gamma))
plt.figure(figsize=(10,6))
plt.plot(dates, sol[:,0] / N, 'b', label='Susceptible (estimation)')
plt.plot(dates, sol[:,1] / N, 'r', label='Infected (estimation)')
plt.plot(dates, sol[:,2] / N, 'g', label='Recovered (estimation)')
ax1.plot_date(dates[:len(I)], I / N, 'or', label='Infected (observation)')
ax1.plot_date(dates[:len(R)], R / N, 'og', label='Recovered (observation)')
plt.legend()
plt.xlabel('Date')
plt.ylabel('Population')
plt.title('Prediction of Covid-19 epidemic in ' + target_pref_str)
plt.show()
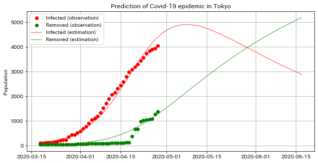
推定結果によれば、GWを開けてすぐには感染者数の上昇はピークに達し、その後緩やかに流行は収まっていくという結果になっています。 本当でしょうか…?
ベイズモデルによるパラメータ推定と予測
次に本命ともいえるテーマです。ベイズでSIRモデルを表現してみて、感染率、除去率、予測の事後分布を推定してみます。
以下の論文が似たようなことに挑戦していたので、これを真似してみました。
Contemporary statistical inference for infectious disease models using Stan: https://arxiv.org/abs/1903.00423
Stanではintegrate_ode関数で微分方程式の計算を表すことができるようです。
これに則って、感染者数、除去者数がポアソン分布に従って発生するとして、以下のようなモデルを書いてみました。
model_code = """
functions {
real[] sir(real t,
real[] y,
real[] theta,
real[] x_r,
int[] x_i) {
real dydt[3];
dydt[1] = - theta[1] * y[1] * y[2] / (y[1] + y[2] + y[3]);
dydt[2] = theta[1] * y[1] * y[2] / (y[1] + y[2] + y[3]) - theta[2] * y[2];
dydt[3] = theta[2] * y[2];
return dydt;
}
}
data {
int T;
real y0[3];
real t0;
real ts[T];
int I[T];
int R[T];
}
transformed data {
real x_r[0];
int x_i[0];
}
parameters {
real beta;
real gamma;
}
transformed parameters {
real y_hat[T, 3];
y_hat = integrate_ode_rk45(sir, y0, t0, ts, {beta, gamma}, x_r, x_i);
}
model {
beta ~ normal(0, 10);
gamma ~ normal(0, 10);
for (t in 1:T) {
I[t] ~ poisson(max({y_hat[t, 2], 0.0}));
R[t] ~ poisson(max({y_hat[t, 3], 0.0}));
}
}
generated quantities {
real y_pred[T, 3];
y_pred = integrate_ode_rk45(sir, y0, t0, ts, {beta, gamma}, x_r, x_i);
}
"""
このモデルでは、SIRの微分方程式をfunctionsブロック内で定義し、integrate_ode_rk45でルンゲ・クッタ法による数値解を求めています。
感染率\( \beta \)と除去率\( \gamma \)に正規分布の事前分布を設定し、観測データ(感染者数\( I \)と回復者数\( R \))がポアソン分布に従うとしてモデルを構成しています。
MCMCによるサンプリング
これをMCMCで解いて、y_hat, beta, gammaから予測、感染率、除去率のサンプリング結果を得ます。
たとえば、東京・大阪・福岡・愛知の4つの都道府県で、それぞれベイズ推定を行い、得られたパラメータで今後の流行予測を可視化してみます。
fig_save = plt.subplots(nrows=2, ncols=2, figsize=(20, 15))
axs = fig_save[1].flatten()
for i, target_pref_no in enumerate(['Tokyo', 'Osaka', 'Aichi', 'Fukuoka']):
# データ準備
t_obs = np.arange(1, len(I)+1).tolist()
t_obs_pred = np.arange(1, len(I)+n_pred+1).tolist()
stan_data = {
'T': len(t_obs),
'y0': [S[0], I[0], R[0]],
't0': 0,
'ts': t_obs,
'I': I.astype(int).tolist(),
'R': R.astype(int).tolist(),
}
# コンパイルとサンプリング
sm = pystan.StanModel(model_code=model_code)
fit = sm.sampling(data=stan_data, iter=2000, chains=4, warmup=500, seed=42)
# 予測結果の取得
y_hat = fit.extract()['y_hat']
beta_samples = fit.extract()['beta']
gamma_samples = fit.extract()['gamma']
予測結果の可視化コード
得られたサンプリング結果を用いて、以下のように流行予測を可視化するコードを作成しました。
# 予測用のデータ
t_obs = np.arange(1, len(I)+1).tolist()
n_pred = 50
t_max = len(I) + n_pred
t_all = np.arange(1, t_max+1).tolist()
# 予測の再計算
stan_data_pred = stan_data.copy()
stan_data_pred['T'] = len(t_all)
stan_data_pred['ts'] = t_all
# 可視化
y_hat = fit.extract()['y_hat']
median = np.median(y_hat, axis=0)
lower = np.percentile(y_hat, 2.5, axis=0)
upper = np.percentile(y_hat, 97.5, axis=0)
ax = axs[i]
# 実データ
ax.plot_date(dates[:len(I)], I, 'or', label='Infected (observation)')
ax.plot_date(dates[:len(R)], R, 'og', label='Recovered (observation)')
# 推定結果(中央値と95%信用区間)
ax.plot(dates, median[:, 1], color='r', alpha=0.7, linestyle='dashed', label='Infected (estimation)')
ax.fill_between(dates, lower[:, 1], upper[:, 1], color='r', alpha=0.1)
ax.plot(dates, median[:, 2], color='g', alpha=0.7, linestyle='dashed', label='Recovered (estimation)')
ax.fill_between(dates, lower[:, 2], upper[:, 2], color='g', alpha=0.1)
ax.legend()
ax.set_xlabel('Date')
ax.set_ylabel('Population')
ax.set_title('Prediction of Covid-19 epidemic in ' + target_pref_str)
plt.tight_layout()
plt.show()
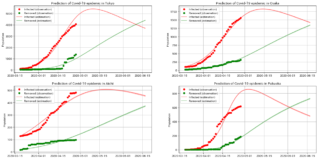
予測結果の考察
東京や大阪に関しては、データ数も多く、そもそも報告の結果も滑らかになっていたためか、とてもフィットしているように見えます。 最尤推定の時の結果と同様に、東京および大阪は、ゴールデンウィークを開けてすぐの頃にピークに達した後に、徐々に収束に向かうような感じになりました。
愛知、福岡に関しては、そもそもあまりフィットしていなさそうです。 このモデル自体に、表現の振る舞いに強い条件がついていそうな気がします。
事後分布の可視化
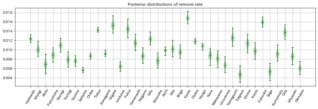
コードは省略しますが、今度はデータが取れている都道府県すべてに対してベイズ推定を実施し、回復率・除去率の事後分布を可視化したものが以下になります。
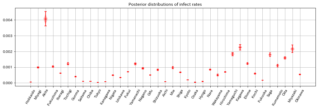
感染率が高いと推定されている都道府県は、事後分布の幅も広い傾向にあります。 調べてみるとデータ数も少し少なめで信頼性の観点で懸念はありそうです。
逆に、人数が多い都道府県の感染率が低いという傾向が見られます。 SI自体を入力しているわけではないのですが、ちゃんとこの辺りの人数に関係して推定しているのかもしれません。
除去率に関しては、確かにデータを見ても感じましたが、東京は、人数や感染者数に対してあまり除去されていない感じであり、結果としてパラメータも相対的に低めに推定されたのかなと思います。
まとめ
今回は、SIRモデル x 最尤推定とベイズ推定を用いて、新型コロナウイルスの感染者数の予測を試みました。
Pythonを使用して実装したコードとその結果も紹介しましたが、皆様もぜひ手を動かしてみて、自身の知見を深めていただければと思います。
感染症の拡大予測は不確かな要素が多く含まれますが、それでもなお、予測モデルを通じて得られる洞察は、私たちが理解し、適切な対策を講じるうえで重要なものになると考えています。
最後に、私たち一人一人が行動を変えることが、全体の感染者数を抑えるうえで最も重要な要素であることを忘れないようにしましょう。 一日も早い終息を願います。
参考文献
- SIRモデル – Wikipedia
- Chatzilena, A., et al. (2019). Contemporary statistical inference for infectious disease models using Stan. arXiv preprint.
- 荻原和樹. COVID-19データリポジトリ: https://github.com/kaz-ogiwara/covid19
- PyStan公式ドキュメント: https://pystan.readthedocs.io/
- SciPy公式ドキュメント(odeint): https://docs.scipy.org/doc/scipy/reference/generated/scipy.integrate.odeint.html
2026年時点の補足
- 新型コロナウイルス感染症(COVID-19)については、WHOが2023年5月に「国際的に懸念される公衆衛生上の緊急事態(PHEIC)」の終了を宣言し、日本においても2023年5月8日より感染症法上の分類が5類に移行しました。パンデミックとしての流行は収束を迎えましたが、季節性の流行は引き続き観測されています。
- 本コラムで用いたSIRモデルは、感染症の流行動態を理解するための基礎的かつ重要なモデルです。COVID-19のパンデミック期間中、SIRモデルやその拡張モデル(SEIR、SIRDなど)は世界中の研究機関で広く活用され、政策決定の参考にもなりました。一方で、実際の感染動態には人々の行動変容・ワクチン接種・変異株の出現など多くの要因が絡むため、単純なSIRモデルだけでは十分に予測しきれないケースも多く見られました。
- 本コラムで使用しているPyStanについては、バージョン3系への移行が進んでおり、APIが大幅に変更されています。本コラムのコードはPyStan 2系の記法に基づいておりますので、現在の環境で実行する際にはPyStan 3系またはCmdStanPyへの移行をご検討ください。
- Stanにおける微分方程式の記述についても、
integrate_ode_rk45は非推奨となり、ode_rk45関数への移行が推奨されています。 - 振り返ってみると、このような予測モデルの構築を通じて得られた知見は、次なる感染症への備えや、疫学モデリングの理解を深めるうえで依然として有用であると考えます。